Commvault Unveils Clumio Backtrack - Near Instant Dataset Recovery in S3
Amazon S3 Backup
Frequently Asked Questions


Data loss from Amazon S3 can occur due to a variety of reasons, including accidental deletions, misconfigured buckets, weak credentials leading to malicious wipeouts, ransomware, insider threats, human error, and others.
Creating a backup of Amazon S3 provides a way to recover lost data and avoid extended downtime. In addition, Amazon S3 backup can also help to protect against data loss due to future problems, such as new malware variants or unforeseen operational disruptions. As a result, Amazon S3 backup should be an essential part of any organization’s cloud data protection strategy.
What is Amazon S3 Backup?
Amazon S3 backup is a process of copying Amazon S3 data from one location to another for the purposes of protection and recovery in the event of data loss.
Why do I need to backup S3?
Amazon S3 is a reliable and durable storage option for businesses of all sizes. However, like any storage solution, it is not immune to data loss. This is why it is important to create backups of your Amazon S3 data. While Amazon S3 does offer versioning and replication, these features are not sufficient to protect against all data loss scenarios. For example, accidental deletion or an insider threat could result in data being removed from S3 without any way to recover it. Furthermore, even if data is replicated across accounts or regions, it is still vulnerable to being corrupted or deleted. The only way to safeguard against these risks is to back up S3 data with an air gap backup solution, storing immutable copies outside your main access control domain.
What S3 data should I backup?
Depending on the business, there are different types of data that should be backed up in Amazon S3. Firstly, any data that is considered business-critical should be protected. This could include critical application data, sensitive information such as intellectual property or nonpublic business data, data lakes that host machine learning training datasets, and more.
Any data that is required for compliance should be protected in accordance with data regulations. For instance, many records are required to be retained for up to 7 years, and regulations such as HIPAA require that backups be air-gapped. Compliance-focused data can include things like financial records, patient records, and Personally Identifiable Information (PII).
What is the best way to backup S3 data?
If you need to ensure that your S3 data is never lost, an air gap backup is the best option. This means that the data is stored separately from your primary control access domain. Ideally your backups should also be immutable. This means the backups are impossible to alter or delete.
Another best practice is to ensure you have the ability to perform point-in-time recovery. This is crucial in the case of corrupted or overwritten data to ensure you get back to the last known good state. Granular backup and restore are important considerations given the immense scale and variety of data in S3.
It’s cost-effective to be able to backup and restore only necessary data to save cost and time.
Does Amazon S3 protect my data?
Amazon S3 is famous for having 11 9s of durability. While this ensures an incredibly low probability of data loss due to issues with AWS infrastructure, it’s important to know that this durability is not the same thing as data protection.
There are numerous reasons your S3 data could be changed or deleted, including accidental deletion, accidental overwrites, internal bad actors, or cyberattacks. None of these events are prevented by S3’s durability. In fact, AWS states that it is the customer’s responsibility to backup their data to protect it from issues like these, as part of their ‘shared responsibility model’.
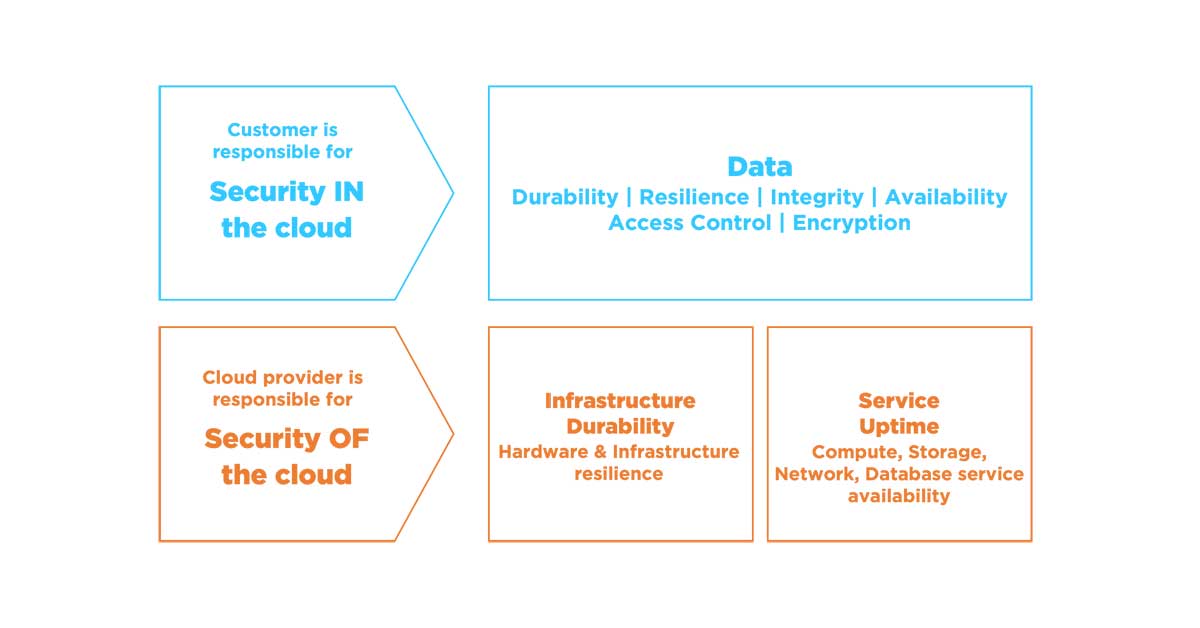
What is the shared responsibility model of Amazon S3?
Shared responsibility model means that AWS is responsible for the security of the cloud, and the user is responsible for the security in the cloud. In simple words, it means that data is the responsibility of the user.
Shared responsibility model provides users with control over their own data, letting them implement their own protection policies and air-gaps, and use the tools to best recover their data in the event of data loss.
The Shared responsibility model is based on three pillars:
Security of Data
The user is responsible for securing their data. This includes encrypting data and backing it up regularly, as well as ensuring access control.
Security of Infrastructure
AWS is responsible for securing the underlying infrastructure that user use to run their applications. This includes physical security, network security, and host hardening.
Operational Security
Both AWS and the user are responsible for operational security. This includes tasks such as patch management and log monitoring.
What is the difference between S3 replication and backup?
S3 replication and backup are two storage strategies that are often confused. Both involve making copies of data, but there are important differences between the two. S3 replication is designed to be a failover in case of outages, while backup is intended to keep an air gapped copy for data recovery from cyber attack, accidental deletion or unintentional overwrite.
In terms of implementation, S3 replication is usually done in real time, while backup is usually done on a schedule, as frequently as every 15 minutes. This schedule is a reason why backup allows for easier point-in-time recovery.
What are the key factors to keep in mind when backing up S3?
When backing up AWS S3 data, there are a few key factors to keep in mind in order to ensure data integrity and recovery. First, it is important to create an air gap between the live data and the backup in order to prevent corruption or infiltration by bad actors.
Second, the backup should be immutable, meaning it cannot be modified or deleted. Third, the backup should be taken at regular intervals, typically at least once a day, in order to have discreet point-in-time copies available. Fourth, the backup should be flexible enough to allow for specific files or object recovery if necessary.
And finally, the backup solution should be able to handle the scale of your S3 environment, whether you have gigabytes of data or petabytes, and whether your S3 buckets contains 30 objects or 30 billion. By keeping these factors in mind, businesses can ensure that their data is safe and can be recovered in the event of corruption or loss.
What is versioning in Amazon S3 and how does it work?
Amazon S3 versioning allows you to store multiple versions of an object in the same bucket. When versioning is enabled for a bucket, Amazon S3 stores all versions of an object (including all writes and deletes) in the bucket. This allows you to preserve, retrieve, and restore every version of every object in your bucket.
To enable versioning for a bucket, you can use the Amazon S3 console, the AWS SDKs, or the Amazon S3 REST API. Once versioning is enabled, you can use the same tools to store, retrieve, and delete versions of objects in the bucket.
One important thing to note is that when you delete an object with versioning enabled, Amazon S3 stores a delete marker for the object, but does not actually delete the object. This means that the object is still stored in the bucket, but is not visible when you list the contents of the bucket. You can permanently delete an object by deleting all of its versions, including the delete marker.
You can also use versioning to preserve objects during a bucket or object restore operation. When you restore an object, Amazon S3 creates a new version of the object that includes all of the data in the previous version, plus any additional writes or deletes that occurred during the restore process.
How does versioning affect the cost of storing objects in Amazon S3?
Enabling versioning for a bucket in Amazon S3 can affect the cost of storing objects in the following ways:
-
Storage costs
When you enable versioning for a bucket, Amazon S3 stores all versions of an object (including all writes and deletes) in the bucket. This means that the total storage cost for the bucket will be higher, as you are paying for multiple versions of each object.
-
Request costs
When you retrieve a version of an object from a versioned bucket, you are charged for a GET request. If you retrieve multiple versions of an object, you will be charged for multiple GET requests.
-
Transfer costs
When you enable cross-region replication for a versioned bucket, Amazon S3 replicates all versions of objects in the bucket (including all writes and deletes) to the destination bucket. This can increase the cost of transferring data between regions.
Overall, the cost of storing objects in a versioned bucket will depend on the number of versions of each object and the storage and request activity for the bucket. You can use the Amazon S3 pricing calculator to estimate the cost of using versioning and other Amazon S3 features.
Is backing up S3 difficult?
Backing up Amazon S3 can be difficult, but it doesn’t have to be. When companies try to build their own S3 backup solution, they find it takes months or even years of effort by a dedicated engineering team. This takes resources away from core business activities in addition to being costly and difficult.
The ongoing management of infrastructure and resources, along with managing day to day backups require an ongoing investment of time and resources. An easy-to-use and more economical solution is to use a SaaS backup solution like Clumio. This allows near-zero time to value, and the ongoing benefits of minimal management time, in addition to saving money.
How can I backup S3?
There are surprisingly few options available to make true backups of S3 data. To get the most out of your S3 backups, make sure it’s air gapped and immutable to provide the best possible protection from cyber attacks and accidental deletions.
Your data should be encrypted end-to-end, and the backup solution should easily fit within your security infrastructure, with multi-factor authentication, single sign on and role-based access controls.
Since S3 stores such a vast amount of different kinds of data, it’s important to be able to easily control which data is backed up and which is not, and to protect different data in accordance with compliance requirements.
On top of all these features, a backup solution for Amazon S3 should be simple to use and economical. Clumio is the only cloud backup solution that does all of these things, making it the best choice for backing up your S3 data. Try Clumio free for 14 days
What is an S3 data lake?
A data lake is a repository that stores large amounts of disparate and unstructured data, in a way that makes it readily available for processing and analytics. Amazon S3, part of Amazon Web Services (AWS), is one of the world’s most popular storage technologies to build data lakes.
What is the difference between an S3 data lake and a data warehouse?
Data lakes are different from data warehouses in two ways. While data lakes store unstructured data in its native format, such as images, media, objects, and files, data warehouses generally store structured data formats like databases and tables. The other key difference is that data in a data lake is generally in the customers’ custody—it resides in their account, and the customer is responsible for its protection, compliance, and security. In a data warehouse, customers usually have to migrate their data into a data warehouse provider and pay the cost of storing this additional copy. The data warehouse provider, however, takes care of the encryption and resilience of the data.
AWS has both data lake and data warehousing services, called AWS Lake Formation, and Redshift, respectively. Both approaches need data cleansing, transformation, and quality engineering for them to be useful for downstream applications such as data visualization, data integration, data modeling, and data science.
How do I set up the S3 data lake?
Just log into your AWS console, select from an available data lake solution such as AWS Lake Formation, and start ingesting data into it. The data lake will store data on S3, and you will have the responsibility to secure and backup this data.
What is the difference between data lakes and ETL?
While data lakes and ETL and both used in the context of data management and analytics, they have different use cases. ETL, or Extract, Transform, and Load, involves the extraction and aggregation of structured data from multiple sources, and then loading it into a data warehouse. ETL is traditionally a ‘big data’ concept. Data lakes, on the other hand, can be read directly for data analytics and data science applications. The customer always has control of the data, which significantly simplifies data architecture.
What security measures should I take to protect my S3 data lake?
Amazon S3 data lakes can be secured using access control methods, encryption, and backups. Access control helps reduce unauthorized access to the S3 data lake. This can be done using AWS IAM roles and enabling multi-factor authentication. The next layer of security is encryption.
Encryption ensures that even if there is a data leak or data breach due to failed access control, the resident data cannot be read by a third party. AWS provides key management systems (KMS).
The final line of defense for data security in data lakes is backups. Backups will ensure that even if a data lake is ransom-encrypted or deleted or wiped out, it can be recovered quickly to a last-known good point in time. Backups are also essential for data compliance with various industry regulations. It is crucial that your backups are air gapped, so even if your entire account is compromised, your critical data is still unharmed and can be recovered to a last known good point in time.
What are the costs associated with an S3 data lake?
Data lake architectures usually incur costs for storage, data pipelines, and data processing.
Why should I backup an S3 data lake?
Backups are essential for the security, resilience, and compliance of your data lake. Here are some benefits:
Protection against accidental deletion or corruption
While S3 itself is a durable service, your data on S3 is still susceptible to accidental deletions, human errors, software overwrites, or faulty data migrations. Backing up your S3 data lake ensures that no matter which of these scenarios occur, your data lake can be restored to a previous version.
Ransomware recovery
In case of a mass encryption event like a ransomware attack, data lake backups can help you recover to a last known good point in time and resume operations without having to pay a ransom.
Compliance with industry regulations
If you have a data lake with sensitive data that needs to adhere to industry regulations, you may be required to maintain air gapped backups of that data. Some important regulations that mandate backups include HIPAA in healthcare, and PCI-DSS in finance. Backing up your S3 data lake ensures data compliance with these regulations.
Disaster recovery
In the event of a regional failure or outage, having a backup of your S3 data lake can be critical for disaster recovery. While most customers use a secondary site that replicates their data for DR scenarios, doing so for data lakes can incur exorbitant costs. Therefore, if your data lake use case can withstand a few hours of downtime, backups can be a cost-effective approach for recovering data lakes from outages.
Data analysis
Data lake backups also enable historical data analysis, trend lines, and metrics on security, performance, and usage across a wide range of time.
More Amazon S3 resources


// Blog
Backing up Amazon S3: Details and Best Practices
I want to share with you some important details to consider when thinking about protecting your d...


// Blog
A closer look at speed and scale results when backing up Amazon S3

// Webinar
Amazon S3 needs modern backup, here’s why
Following the 2nd Special Edition of Backing up Amazon S3 for Dummies!, we discuss why Amazon S3 ...