Commvault Unveils Clumio Backtrack - Near Instant Dataset Recovery in S3
Atlassian
How Atlassian improved JIRA Cloud resilience
Clumio’s game-changing approach to cloud data backup and recovery has been instrumental in tackling some of our biggest data resiliency challenges.
Atlassian unleashes the potential of every team. Their collaboration software products like JIRA and Confluence help teams organize, discuss and complete shared work.
Atlassian saw an opportunity to improve the resiliency of their JIRA Cloud product, with critical customer data in Amazon S3 to the tune of 40 billion objects at 43 petabytes, and more than 1 million changes per hour. A previous backup effort had yielded a longer than ideal recovery time, a lot of API operations, and a high cost.
With Clumio, Atlassian was able to backup an initial 24.5 billion objects in 17 days, without application impact. Their critical customer data is now backed up continuously and securely, with a 15-minute RPO, and at a 70% reduction in cost.
Transcript

Woon: My name is Woon, I’m the co-founder and CTO of Clumio. And today I have Andrew Jackson from Atlassian.
Andrew: Thank you Woon. Hi, everyone. My name is Andrew. I’m a Senior Engineer at Atlassian, and I spend my days working with teams to solve problems surrounding data. With my most recent focus being disaster recovery. It’s an absolute pleasure to be here today to talk a little bit about our successful collaboration with Clumio, and how their game changing approach to cloud data backup and recovery has been instrumental in tackling some of our biggest data resiliency challenges.

Andrew: I’m going to quickly run through the agenda for today’s session.
- I’m going to provide some context about Atlassian and what we’re all about, and details like a high level walk through of our architecture.
- Then I’ll touch through one of the most complex problems in this line of work, data resiliency.
- I’ll provide some of the complexities and challenges associated with the space.
- Then I’ll pass it over to Woon who will delve deeper into the efforts required to provide a highly performant and highly scalable S3 backup solution.
- And then we’ll come together, talk a little bit more about the implementation at Atlassian specifically, as well as the benefits achieved.

Andrew: So what is Atlassian? At its core, it’s a company that drives innovation and collaboration, with the mission being simple yet powerful, to unleash the potential of every team. And Atlassian helps facilitate this by providing software that you probably use already in your day-to-day work. Some of you may have already used JIRA for project management capabilities, Confluence for extensive content collaboration, Bitbucket for source code management, or even Trello to organize tasks in a fun and flexible way. Those are just four of a variety of different products we provide.

Andrew: But in line with the mission, it’s not necessarily about the range of the products, but more about how they’re used. And since being founded in 2002, Atlassian has amassed over 260,000 customers worldwide with some of the biggest names in various industries. What that really means is that whether you’re coming from a small startup or a large enterprise, these tools have been available to help streamline processes, enhance productivity, and foster innovation.
But with 260,000 customers, the amount of data that we have to process daily is vast, not just vast in terms of the volume of data, but also because of the requirements and compliance standards associated with that data. So I’m going to quickly walk through the high-level architecture to give you some ideas about how we operate.

Andrew: At its core, Atlassian is powered by a variety of different AWS services, including compute, data, network, and storage-related services. These services underpin Atlassian’s own internal platforms and services that in turn provide capabilities for our products. And these product capabilities include things such as the JIRA issue service, or Confluence analytics. You’ve got things like the editor in Confluence, as well as media identity and commerce for anyone familiar with those aspects.
Typically an Atlassian product consists of multiple containerized services that have been deployed on AWS using our in-house provisioning layout micros, which effectively orchestrates our AWS deployments. And these services contain a variety of different features from request handling, transactional user generated content, authentication management, data lakes, observability and even analytical services. And with all these different services powering the Atlassian ecosystem, we need to have extremely strong foundations, which in this environment is our data source.

Andrew: For that purpose today, I’ll focus on S3, because S3 in itself is probably the largest data store we’ve got due to the vast variety of data that has to be received and processed daily. Now, with such a significant architecture comes equally tricky challenges. First off, in an era when data is vital, it actually becomes an increasingly complex task to handle the amount of data that we’ve got, as more unique ways to view and transform data actually occur every day. And that means it becomes harder to guarantee our requirements are satisfied.
The second aspect of it is that compliance and scalability are crucial. It was becoming an arduous task to guarantee requirements were satisfied as more and more customers onboarded to our platform. And what this really meant is that these challenges are not just operational hurdles, but they’re actually impediments to the quality experience that people expect from Atlassian.
And so we knew that there had to be a data backup solution that didn’t just meet our requirements for minimal downtime and quick recovery, but could actually tick off some of these requirements, like 99.95% uptime, data residency controls, and one hour RPO. These are just the highlights of those requirements, but there are substantially more.
And so we were keen to find out what was on the market. We investigated internally, and luckily Clumio reached out to us after seeing our interest in the space. We collaborated very closely, and through that collaboration we were able to obtain an optimal solution that enabled us to back up the S3 data at that scale of the 40 petabytes, whilst at the same time ensuring that we had safety and accessibility in the event of unforeseen circumstances.
I’m going to pass it over to Woon, who will delve a little bit deeper into the efforts required to provide such an optimal solution that has effectively exceeded our expectations in that space, turning those challenges into a success story.
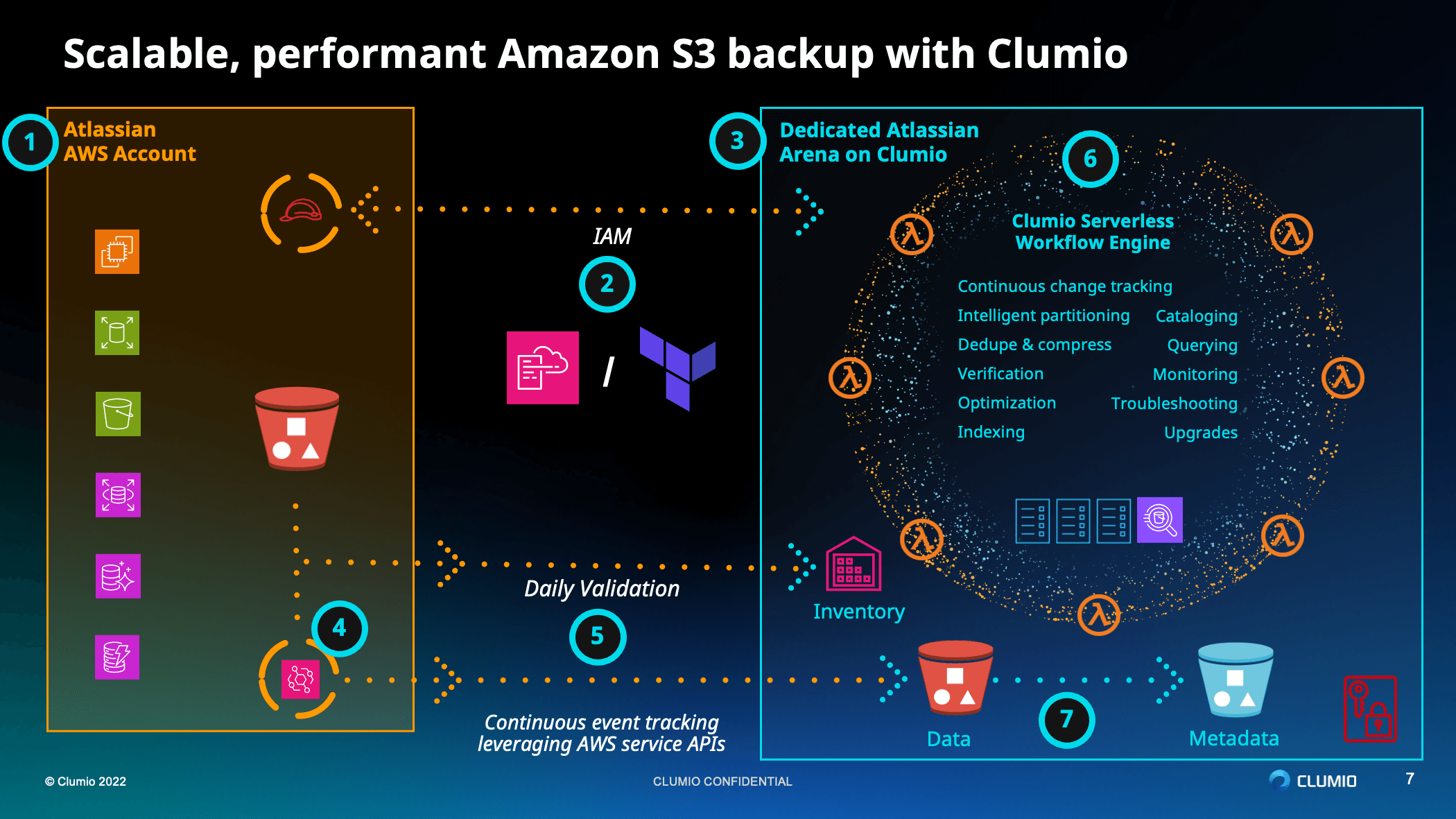
Woon: Thank you, Andrew. What I want to start with first is the high level overview of the architectures, and then go deeper. First of all, on the left hand side, we have the customer account, which in this example would be Atlassian’s AWS account. That bucket in the middle is the bucket that we’re trying to protect.
The way that you onboard is pretty straightforward. You onboard by installing either a CloudFormation Template or a Terraform that we provide. Obviously, every environment is unique, so we also allow you to customize that CloudFormation Template to fit your needs in your environment. Once that CloudFormation template is installed, we install all the assets needed to carry out the backup.
For example, an IAM role gets created in your AWS environment that we use to carry out all the operations needed for backups. Along with that, we also install things like S3 inventory and S3 Event Bridge. These are all mechanisms for us to get that list of objects to be backed up.
The S3 inventory will get us to the full list of the objects, whereas the S3 EventBridge will get us the Delta, or the changes happening in your bucket minute by minute. And these are the technologies that allow us to build continuous backups. We backup every 15 minutes, providing the 15 minute RPO through that Event Bridge integration.
Once that is set up, on the right hand side is everything that is actually managed by Clumio. This includes all the processing, cataloging, and data verification that all happens on the Clumio side with the entire architecture being serverless. It actually scales up and down based on the load that you have.
If there are a lot more objects to be backed up, we’ll employ more Lambda functions, and if there are less, we’ll employ fewer Lambda functions, but all that is actually completely managed by us. And then on top of that, all this processing happens and the data is housed in a separate account that is dedicated for that one customer. So in this example, this account is dedicated for Atlassian, and all the data processing and housing of the data happens in that account.
If I move on, in this presentation we’ll talk about some of the innovations in the backup space and the ingestion layer that allow us to backup large buckets like the ones that Atlassian have.
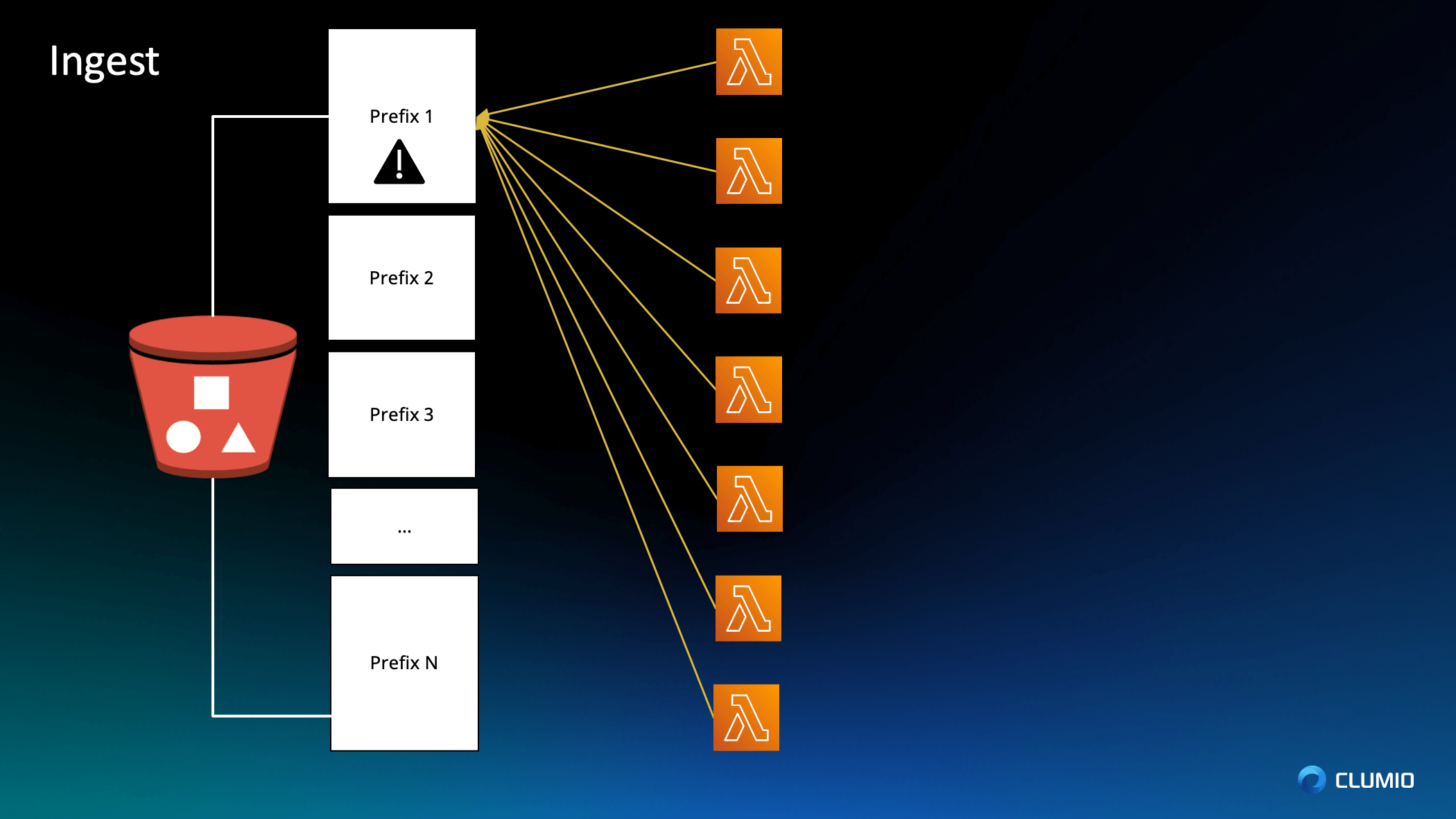
Woon: So let’s start first with the bucket again on the left hand side. So imagine that you have a bucket with thirty billion objects. You have objects starting with the prefix A, all the way to prefix Z all sorted in that list. So at a high level, you might think, how hard could it be, right?
You fire up a bunch of lambda functions and you start copying objects out and that’s basically your backup. But not so quick. If you have a ton of lambda functions and you schedule them in a way they all work on the same prefix, then what’s going to happen is that you’re going to hit the API limit before anything else.
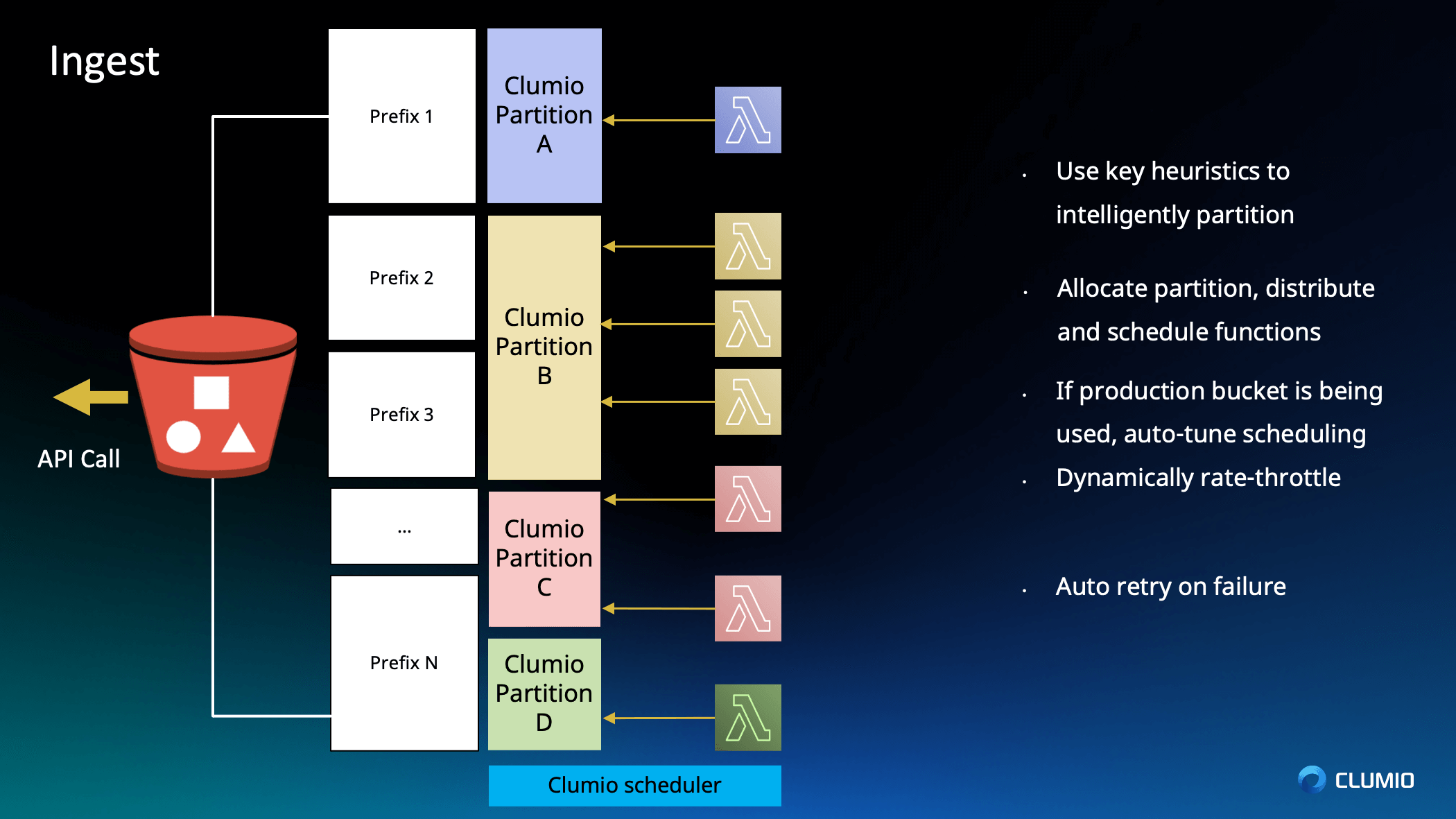
Woon: So that bucket, the primary application is the primary owner of that bucket. So if the backup operation goes and steals all the API requests per second, all the TPS, then guess what? The primary application is the one that suffers. It’s the JIRA tickets that are going to load slowly, or the attachment that is not going to load in in a speedy manner.
So what we do is that we’re constantly looking at the API back pressure. So we observe and track the API back pressure, and schedule accordingly. So if we see a ton of back pressure happening on partition A, we actually reschedule the lambda functions to actually give a little bit of a break to partition A, and we actually do a little bit more work on partition B because there’s more capacity there. And this process happens all the time, dynamically, up until the backup is complete. All of this is actually automatic and managed by Clumio.
So just to sum up my part end to end; Onboarding is pretty straightforward. It’s really a Terraform template, 15 minutes you’re up and running. All that complexity that I talked about, like dynamically scheduling and partitioning, all that stuff happens behind the scenes and is delivered to you as a service. Andrew, you want to take it over and discuss your experience?
Andrew: Absolutely. Because the beautiful thing about these types of results is that once we had that initial backup done within that 17 days, and for context, we actually had substantial challenges getting to that point. Once we got there though, that was huge because it meant now we could actually start working towards the standard that our customers expect from us.
The very first thing that comes to mind when it comes to backup and recovery is RPO. So we wanted to make sure we could provide that one hour RPO when it came to being able to restore data. But what was fantastic was that after some testing and rolling out this feature, we actually were able to identify through our tests that we were meeting a 15 minute RPO, which had practically been unheard of with this level of data.
Once that technical feasibility was handled, then it just became a question of actually tackling the business problems, which for the purposes of this, I’ll talk about two very specific ones. The first one being data residency controls. So the beautiful thing about data residency controls is that you have to make sure that you can easily roll out your controls to new environments as you need to. And the best part about this is that we were simply able to work with Clumio and enable those features for those specific regions, which lifted a substantial weight off our shoulders there and ticked that box in terms of compliance standards.
The second part, which I’m sure everyone loves talking about, is cost reduction, because for context Clumio actually provides an air gapped and immutable solution, and for those not familiar with that, it means that if we wanted to delete our backups, we actually have to go through a very rigid process to do so. So developers can’t just simply knock out their backups.
And by enabling this in place, it meant we could actually revisit some of our existing backup solutions and optimize accordingly, remove some of those resources, and actually apply and tune our approach, which overall resulted in a 70% cost reduction. I can’t stress how huge that is given this type of data that we’re working with. It has made this a major success overall.
Woon: This has been a ton of fun working with the folks at Atlassian. So today we’re in 20 different regions and we’re going to continue to expand to match the regions that Atlassian is using. The level of performance optimizations and the scalability work that we did with Atlassian was a huge amount of fun, and we’re at a position that we can actually back up 30 billion objects in literally two weeks, 17 days, to be exact, while also throttling because we don’t want to impact the primary application. Our partnership and collaboration with the team and Andrew has been a pleasure.
Andrew: Absolutely.

Woon: So this is it. This is the end of the talk and we have our demo. Stop by for the demo or visit us at Clumio.com. Thank you.



About Atlassian
Behind every great human achievement, there is a team.
From medicine and space travel, to disaster response and pizza deliveries, Atlassian’s products help teams all over the planet advance humanity through the power of software.