Commvault Unveils Clumio Backtrack - Near Instant Dataset Recovery in S3
Next-Level S3 Data Protection: Exabyte-Scale & Instant Restore





Managing data resilience in the cloud is hard. Modern apps generate and consume data at a blistering pace and protecting that data is a huge challenge. This is because the building blocks of these apps—microservices and functions—leverage ephemeral compute and use cloud object stores to persist data when needed. This leads to massive, exponentially growing repositories of unstructured data that is very difficult to rein in and secure.

The evolution of applications, from VMs to functions
The challenges of protecting Amazon S3
Amazon S3 has quickly become the leading persistent storage solution for such modern applications, powering data lakes, analytics, and AI. S3 delivers highly durable infrastructure, but data on S3 still needs to be protected. Amazon is clear about customer data being the customer’s responsibility—a principle they call the shared responsibility model.
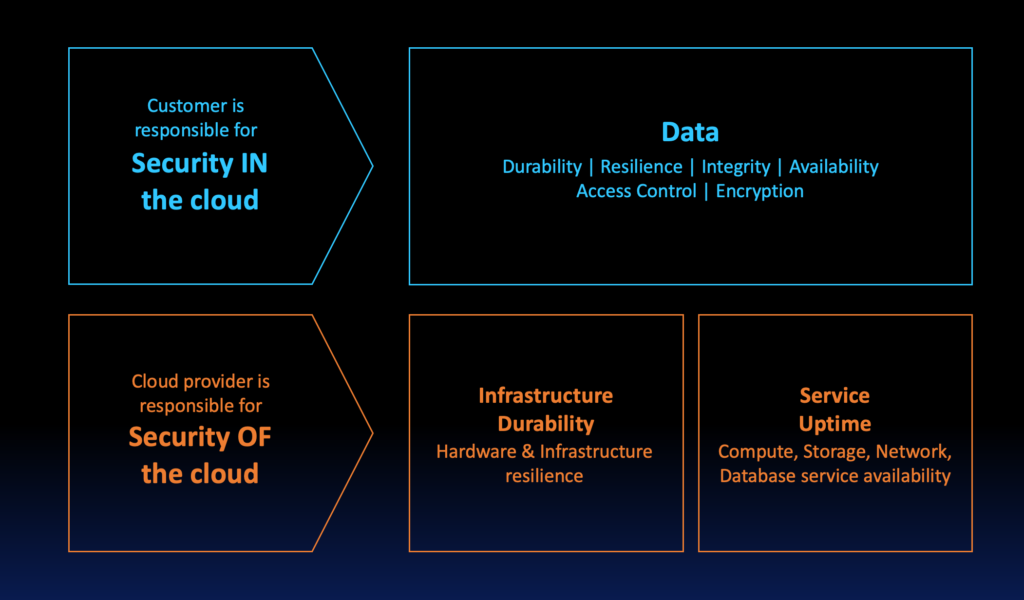
This exponential growth and criticality of S3 has forced customers to rethink their data protection and restoration strategy, as the native and traditional methodologies no longer suffice nor scale.
Every day we talk with customers about their S3 data protection requirements, and I have to be honest, they get more advanced each day.
- “We need MASSIVE scale in both S3 object density as well as volume”
Customers are quickly ramping up to 10s of billions of objects in individual buckets across their S3 estate, totaling capacities in the scale of 10s or 100s of petabytes. - “We need near real-time protection with low RPO”
Once-a-day backups are no longer good enough due to radically increased data entropy. - “We need a near-instant recovery of massive datastores”
Recovery is painful, costly, and time-consuming at the scale of S3. - “We need global visibility with actionable insights”
Determining where data resides is the first step, but taking action is important when issues are identified.
Unfortunately, these capabilities have been non-existent, forcing customers to dysfunctionally leverage myriad tools – or worse, build it themselves – adding vulnerability, costs, and tech debt from manually moving petabytes of capacity around the cloud.
Today, that all changes.
I am excited to announce three new capabilities for Clumio Protect for Amazon S3, which we built in partnership with our customers and the Amazon S3 engineering team, to protect the largest modern, cloud-native applications in AWS:
1. Continuous 15-Minute RPO Backup at 30 Billion Object Scale

Clumio Protect for Amazon S3 now provides continuous point-in-time protection at any scale.
This new addition reduces RPO to just 15 minutes, scale-tested to a staggering 30 billion objects at 100s of PB capacity scale. There is no additional cost for this functionality and no requirement for S3 object versioning to be enabled, further reducing the cost of protection.
To get 15-minute micro-backups we leverage Amazon Eventbridge to provide us with all events. We queue up all the object events over 15 minutes, then we backup the changed objects. To ensure no objects are missed, we leverage S3 Inventory to “true up” the backups so no object is ever missed.

Oh, did I mention we now support the LARGEST S3 customers worldwide with up to 30 BILLION OBJECTS? At Clumio, we like big buckets and we cannot lie!
Continuous point-in-time protection and 30 billion object scale is generally available for Clumio Protect for Amazon S3, so check it out with a 30-day free trial on the AWS marketplace or head over to clum.io/try.
2. S3 Instant Access
As a cloud ops practitioner, wouldn’t it be awesome if you could conjure up a full copy of your data environment without having to move a single bit? Our cloud ops customers serve data to developers, data engineers, data scientists, and compliance teams, but at the large scale of S3, it’s tedious and time consuming to move, copy, and access-control all that data. For backup and restore, it’s even worse. It takes a long time to find the data you want to recover, and even longer to recover the actual data. Wouldn’t it be nice to have an instant, immutable, live copy of your Amazon S3 data?
Today, we are introducing S3 Instant Access, an EXTREMELY LOW RTO solution that gives customers secure, instant access to a point-in-time copy of their data via an S3 endpoint from Clumio.
Live or time-machine copies of entire S3 data lakes at the snap of a finger.

With S3 Instant Access, it is as simple as determining a point in time, naming the S3 instant access, and you receive an S3 endpoint in return to access directly inside of Clumio Protect.
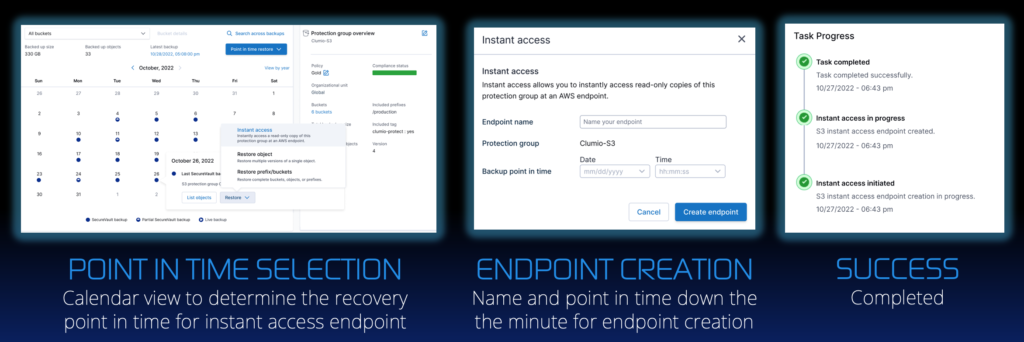
Once you have an endpoint from Clumio, new use cases open up, more than you can imagine. To get your imagination going, here are a few you can get right out of the box:
- Rapid Granular Recovery: Global filtering is sometimes not enough, when you don’t know what to filter by. To find the data you are looking for, you can access your endpoint, browse buckets and prefixes, and restore whatever data is needed with time machine-like functionality through our Continuous Backups without any restoration required.
- Cloud Clones for Cloud-native Applications: Need to spin up product data from today to test in a development environment? S3 Instant Access enables Cloud Clones of massive-scale environments instantly to run testing or batch processes against.
- Instant Disaster Recovery Testing without Restore: Need to run a DR test, but don’t want to wait or pay for the cost of restoring all the data? Run a DR test instantly against our endpoint.

We will demo this technology at our AWS re:Invent booth, so come check it out! For more information on where to find us, check out our blog Redefine Data Protection for Amazon S3 with Clumio at re:Invent 2022. This is only the beginning for S3 Instant Access. Stay tuned for a ton more innovation and use cases to support our customers in the near future.
3. Global S3 Visibility with Actionable Protection
Seeing everything across all your AWS accounts, regions, and services is near impossible, but taking action to remediate issues is some next-level stuff many customers demand today.
We are excited to announce the addition of S3 bucket-level analysis and bucket protection directly in Clumio Discover.
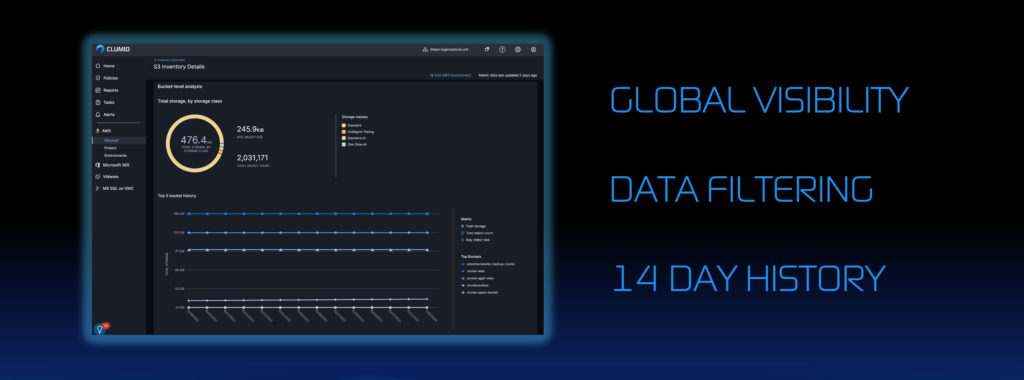
Metrics are supported across all accounts with filtering by tag, account, region, or bucket name. You can see valuable metrics including top storage, top object count, and average object count over the last 14 days. A capacity breakout across each S3 storage tier is also available with average object size and total object count.
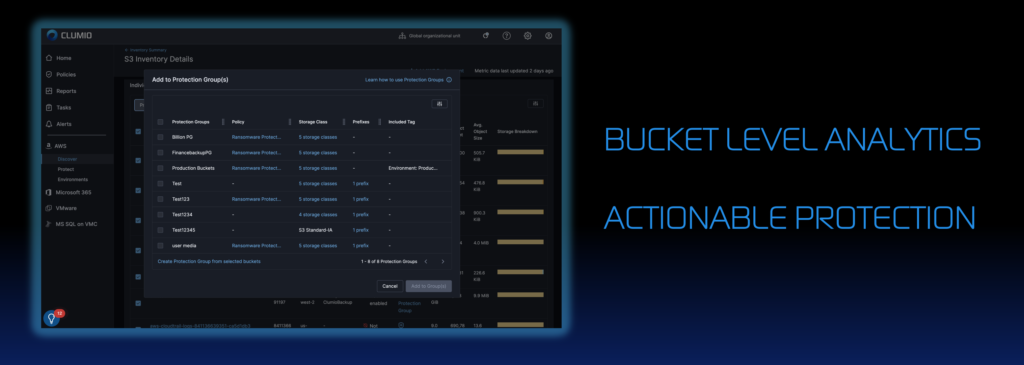
Clumio Discover now also provides the ability to take action when vulnerabilities are identified. You can now see bucket-level details, with the ability to select multiple buckets and add them directly to a protection group. This capability not only saves our customers valuable time, it helps them identify and fix protection gaps they may not have been aware of otherwise. Clumio Discover for Amazon S3 is generally available now!
A ton of fun new innovations just in time for AWS re:Invent! Click here for more information about Clumio Protect for Amazon S3 and S3 Instant Access. Clumio Protect is also available for the protection of Amazon Elastic Block Store (Amazon EBS), Amazon Elastic Compute Cloud (Amazon EC2), Amazon Relational Database Service (Amazon RDS), Amazon Simple Storage Service (Amazon S3), Microsoft 365, and VMware Cloud on AWS with a 14-day free trial. Stay tuned for more and more innovation from Clumio!
Until next time, stay SaaSy my friends! NO SLEEP TILL BROOKLYN!
