Commvault Unveils Clumio Backtrack - Near Instant Dataset Recovery in S3
Enabling near-instant recoverability of large Amazon S3 datasets with Clumio







As organizations start dealing with larger and larger amounts of datasets in building modern business intelligence and machine learning applications, they start adopting data lakes with a central location to store large volume data and a flat architecture to reduce complexity.
Amazon Simple Storage Service (Amazon S3) is the backbone for more than 700,000 data lakes today. Its simplicity, scalability, and durability make it a go-to choice for cloud architects, IT professionals, and developers. With more customers using Amazon S3 to store their most critical data, the need to back up that data for operational resilience, cyber resilience, and compliance purposes has grown exponentially.
Security in AWS is a shared responsibility between the customer and AWS
Amazon S3 operates under this Shared Responsibility Model, which outlines the responsibility of AWS in securing the cloud, and just as importantly outlines the customer’s responsibility in security of their data stored in the cloud. This includes safeguarding against erroneous deletions, threat actors, cyber incidents, and other operational disruptions. The most reliable method to achieve this is by implementing a secure backup and recovery strategy.
Resilience of data lakes built on Amazon S3 also encompasses uptime, especially for time-critical or customer-facing applications. In the face of a disruption, backed up data needs to be restorable near-instantly. To manage both aspects of backup and recovery effectively, this blog will discuss the challenges and solutions related to implementing a backup strategy and ensuring rapid data restoration in a data lake.
The challenges with backup and recovery of large datasets
The volume and growth of data lakes makes protecting it difficult yet a critical task for cloud infrastructure, IT, and cloud operations teams. This primarily comes down to three characteristics of data in Amazon S3–its volume, variety, and velocity.

The 3 challenges of backup and recovery of large datasets
- Data Volume: As customers scale their storage from gigabytes to petabytes or more, they need to classify datasets into critical and non-critical categories. Backing up everything isn’t cost-effective, and engineering a solution for large-scale data backups can be challenging. For customers using Amazon S3 to store petabytes of data, large-scale restores from backups can take days to weeks and time critical applications cannot withstand extended downtime. Full restores can also drive up the cost with data transfer and storage costs.
- Data Variety: The diverse nature of object types, lifecycle rules, change rates, and protection policies (e.g., replicas, versions, tiers, locks) can delay the standardization of data backups across an organization. Specific applications, like those in financial services, require both operational and compliance backups, each with unique schedules, retrieval times, and retention periods. Standardizing and automating backups for various use cases can become complex.
- Data Velocity: Customers execute trillions of requests daily on S3 Data lakes. Conventional methods like daily archives, point-in-time copies, or object versions are inadequate for resilience and prone to failure in operational recovery. Achieving true application resilience demands continuous monitoring of events, changes, and metadata, reflecting them consistently to a secondary environment – all complex engineering challenges.
In this post, we explore how Clumio utilizes Amazon S3 Object Lambda to provide near-instant restores of data in Amazon S3 through the Clumio Instant Access feature for customers.
Clumio–simplifying backup for Amazon S3 data
Clumio, an AWS storage competency partner, simplifies backups for Amazon S3 customers. Clumio is a serverless backup solution that continuously tracks changes across a customer’s Amazon S3 landscape, replicating the data to a storage-optimized, immutable, and air gapped secondary environment with high fidelity. Engineered as a stateless data processing pipeline utilizing a proprietary workflow engine for serverless functions, Clumio’s backup and recovery performance for Amazon S3 is exceptional in both scale and efficiency.
Clumio is now advancing its expertise in S3 backup and recovery through the introduction of Clumio Instant Access. This innovative approach provides a significantly lower Recovery Time Objective (RTO) for recovering Amazon S3 data compared to traditional restores, ensuring continuity of applications and data lakes in the event of an operational disruption or cyber incident.
Building a new paradigm for instant data retrieval
Given the characteristics of cloud-native applications and data lakes, conventional recovery times—often measured in days—are inadequate. Many customers opt to duplicate their entire Amazon S3 environment using active/active or pilot-light architecture, thus storing and incurring costs for twice the amount of data. However, this strategy falls short in scenarios requiring rollback, such as when a revenue-generating application is compromised and needs restoration to a previous stable state. A replicated environment cannot assist in these cases, and traditional restoration might result in hours or even days of downtime. These challenges clearly show that a solution is needed—one that combines the rapid restoration capability of a pilot light architecture with traditional backup features like point-in-time restore and rollback. Customers require a mechanism to swiftly “wake up” their backed-up Amazon S3 data and grant applications immediate access.
Clumio Instant Access allows customers the ability to securely provide their applications with direct access to their backed-up data, filtered to any point-in-time of their choosing, without having to first rehydrate a single byte of data into a customer AWS account. Clumio Instant Access solves the challenge of providing cost-effective, short-term access to large datasets in near-real time. Let us explore how this works.
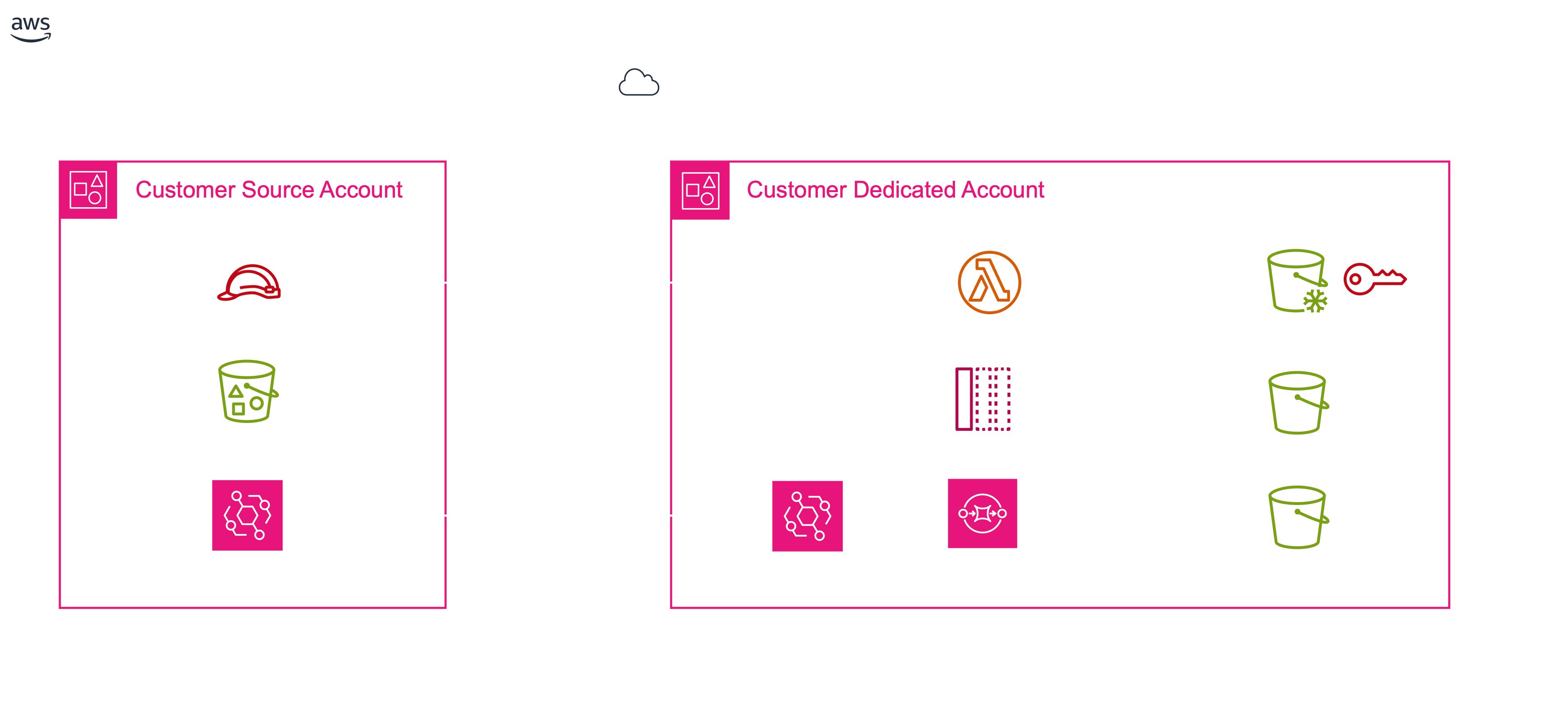
The architecture of Clumio Instant Access builds on its secure air-gapped backups. Clumio backups are serverless and agentless—rather than having the customer deploy third party software in their account, Clumio uses an Amazon CloudFormation template to deploy an AWS IAM role, and perform all necessary compute, storage, and optimization in a separate customer-dedicated, air gapped account.
When a change occurs in their primary S3 bucket, Clumio uses Amazon EventBridge to trigger an event, which is sent to an AWS Simple Notification Service (SNS) topic, which in turn triggers AWS Lambda functions on the Clumio platform. These functions are responsible for capturing the event details such as the exact change (object creation, version change, associated metadata, etc.), processing and storing the change in the metadata catalog, and subsequently storing a copy of the object in the data repository. Data, metadata, and inventory catalogs are housed in separate S3 buckets within the customer-dedicated AWS account outside of their enterprise security domain.
During a restore process, Clumio leverages Amazon Athena to query the metadata catalog and locate the specific object(s) and its requested version(s) in the backed-up data. Because of the event-level change capture, Clumio allows for granular, object-level point in time restores across prefixes and buckets. Clumio’s dynamically scalable lambda-based workflow engine retrieves the target data and orchestrates parallel object copy operations back to the customer’s primary account, dramatically reducing recovery times.
Throughout the process of backup and restore, customer data remains encrypted using a combination of the customers’ Amazon Key Management Service keys, and Clumio’s own encryption keys.
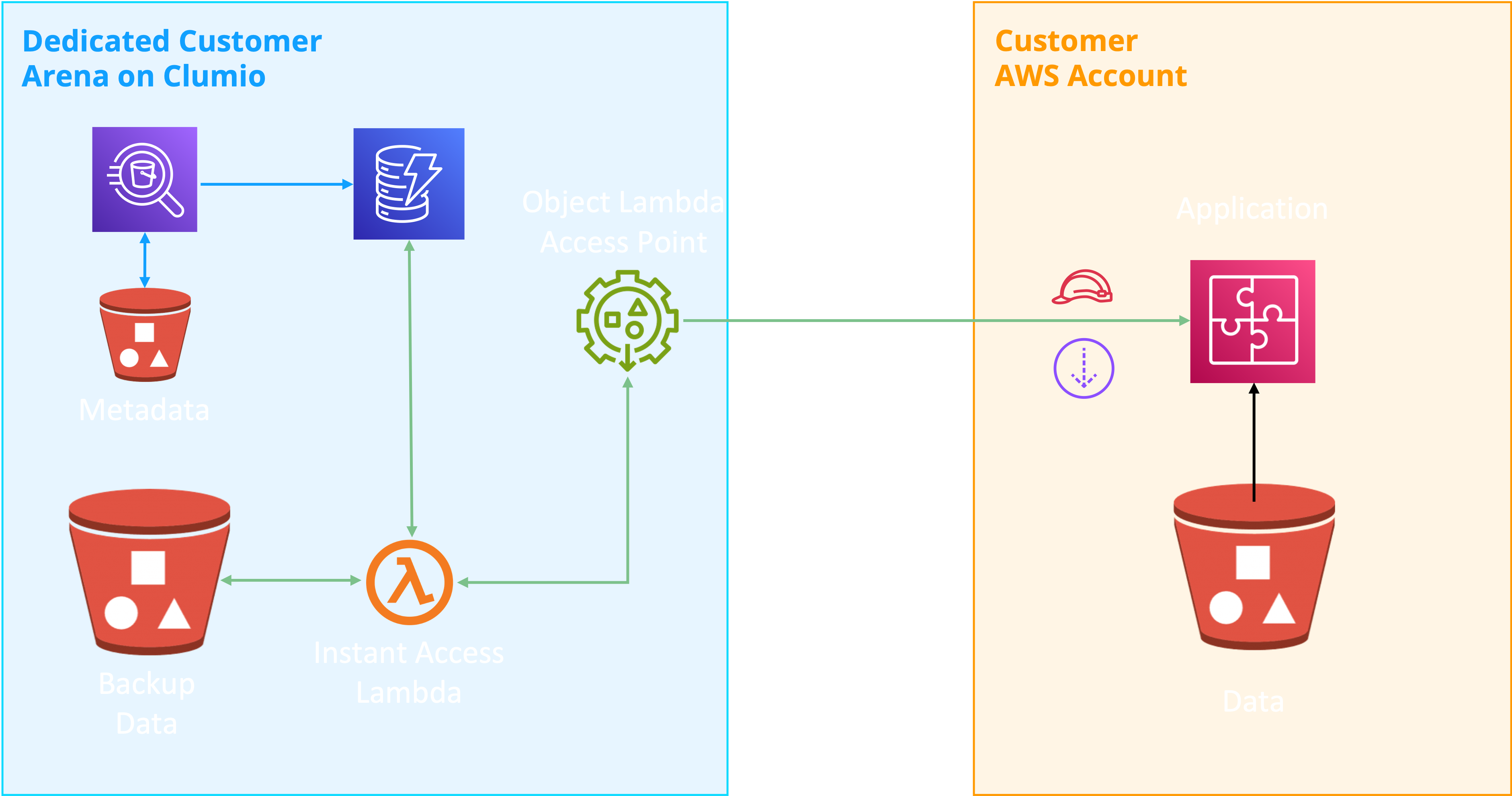
Clumio S3 Instant Access architecture
In contrast, during an Instant Access operation, Clumio retains an addressable copy of the target metadata for sustained access. Clumio Instant Access is built using S3 Object Lambda, which uses AWS Lambda functions to automatically process the output of a standard S3 GET, HEAD, and LIST request. Clumio utilizes this feature to provide customers direct access to backup data through S3 Object Lambda Access Points without needing to wait for the full recovery.
This process involves populating an Amazon DynamoDB table with the Athena query results to preserve the filtered, point-in-time metadata the customer seeks to access. Then, Clumio subsequently employs a S3 Object Lambda Access Point to establish a customer-addressable S3 endpoint, securely accessible through customer-provided IAM roles and/or CloudFront distribution. The S3 Object Lambda Access Point channels each S3 API request received from the customer via the Instant Access lambda, which queries the DynamoDB table to identify the location of the requested data, and subsequently retrieves and returns the object data to the requesting application.
Here is sample performance data on endpoint creation times with Clumio Instant Access.
| 100K objects | 06 minutes |
| 1 million objects | 10 minutes |
| 10 million objects | 18 minutes |
| 100 million objects | 24 minutes |
| 1 billion objects | 36 minutes |
| 30 billion objects | 170 minutes |
This architecture encapsulates both efficiency and security, delivering a robust solution for instant access to data.
Spinning up a secondary data lake in minutes at LexisNexis
Global legal giant LexisNexis maintains a record of nearly every U.S. court case within their Amazon S3-powered data lake. These records and their associated data are paramount to the revenue generating operations at LexisNexis. Naturally, they require robust resilience for their Amazon S3 environment against cyber incidents and operational disruptions. This necessitates the ability to restore tens of billions of S3 objects, amounting to hundreds of terabytes, to a last known good point in time swiftly.
With Clumio’s S3 Instant Access feature, LexisNexis is able to rapidly create a viable secondary data lake, enabling their applications to temporarily link to this data and re-establishing functions quickly. Meanwhile, should a full restoration be required, Clumio’s Lambda-powered architecture ensures the comprehensive recovery of the entire data lake in parallel.
“Clumio Instant Access creates a new way to backup and recover large-scale critical datasets in Amazon S3”, said Mark Seitter, Sr. Consulting Software Engineer at LexisNexis. “Before this solution, it would have taken us days or weeks to restore our vast repositories of unstructured data. By partnering with Clumio and the Amazon S3 team at AWS, we were able to build a solution that reduces recovery time significantly, scales to billions of objects, and costs less than our previous solution. While Clumio maximizes the use of native AWS services such as Amazon S3 Object Lambda, Amazon DynamoDB, and Amazon Athena, the complexity is hidden behind their easy-to-use product interface.”
Conclusion
By eliminating the need to rehydrate data back to the primary environment, Clumio Instant Access for Amazon S3 marks a paradigm shift in data recovery. Clumio Instant Access enables a highly cost-effective, secure, and immediately accessible “time machine” for your Amazon S3 data that your apps and data lakes can leverage. There are some immediate benefits with this approach:
- Minimize downtime: Traditional recovery methods often necessitate protracted restore periods for large S3 datasets, resulting in recovery timelines spanning days or even weeks. Leveraging Clumio Instant Access, data recovery can be streamlined, reducing data retrieval time to mere minutes—a monumental leap in efficiency. With every minute carrying significant cost / revenue implications for critical applications. Clumio’s ability to drastically diminish downtime provides a robust solution to maintain operational continuity.
- Facilitate debugging and testing without a second copy: Clumio Instant Access serves as a versatile tool for development and testing teams, furnishing point-in-time data replicas that deliver a more agile and cost-effective debugging and testing environment.
- Prove compliance: Compliance audits, such as those mandated by HIPAA or FINRA, often require tangible demonstrations of data recoverability. Clumio’s innovative approach allows direct connections to backups, curtailing the time and costs of the audit verification process.
Clumio Instant Access was highlighted at AWS re:Invent in the Lightning Talk STG101-S | Achieving Amazon S3 data lake resilience at LexisNexis. Watch it for free here.
To get started with Clumio, simply head over to the AWS Marketplace.
About the author
Jason is the Product Manager for S3 backup at Clumio. Prior to Clumio, Jason held Principal Solutions Architect positions at data management companies such as Pure Storage, NetApp and Nebulon, where he ushered enterprise customers through successful digital transformation initiatives.