Commvault Unveils Clumio Backtrack - Near Instant Dataset Recovery in S3
Cloud Backup: Why We Need Cloud-Native Data Protection





All enterprises were already using cloud computing in one way or the other when the COVID-19 pandemic suddenly accelerated the migration of additional workloads to the public cloud. There are multiple reasons for this. From the technical point of view the flexibility and agility provided by the cloud can’t be matched by an on-premises infrastructure, while the OpEx model enables organizations to tune budgeting in real time to adapt to the real demands of the business.
At the beginning, most organizations that tried lift-and-shift migrations have come to understand that this approach is particularly inefficient, causing them to rely more on services directly available in the public cloud. In fact, to take full advantage of the public cloud and its TCO, you have to embrace the ecosystem fully.
If you are on AWS and need a database service, for instance, you can dodge all the complexity of building the entire stack made of basic EC2 instances, buying DB licences, installing the DB, configuring it for high availability, and tuning and maintaining it. Instead, you just use AWS RDS, which is not only easier to use and manage, but more optimized and offers much lower TCO than a DIY solution. This is clearly the right approach, however there is a snag: data protection.
Protecting Applications and Data in the Cloud
Most backup solutions were designed before the cloud. They can deal pretty well with physical and virtualized environments but struggle with cloud services. There are several reasons for this, including architectural issues with many products. Usually, we have a backup server, media servers, agents installed on each single machine, and connectors for virtualized environments. In this scenario, applications like databases are managed with specific integrations or additional agents. This type of architecture, whether installed on-premises or in the cloud, is particularly inefficient and becomes increasingly expensive and inefficient over time, swamping any early savings.
A traditional backup product usually uses an agent installed on a cloud VM (an AWS EC2 instance, for example) to make backup copies. The user finds a very familiar environment to operate, but:
- Most of the backup servers still use file volumes to store backups and they can use object storage only later for long-term storage, which adds complexity and cost.
- If the backup target is outside the cloud of choice (on-premises, for example), the user will incur egress fees that, again, will add unforeseen and unpredictable costs in the long term.
- Backup times are quite long and restores can be even longer, with unappealing RTO and RPO figures.
This approach does have its advantages, including the ability to index and search backups, perform partial restores, and manage retention properly,
Some solutions take a different approach and build a wrapper around the standard snapshot API available on the cloud platform. In most cases we talk about a nice user interface to what is usually done via API or CLI. It works, but it doesn’t scale, and over time it can be difficult to find the right snapshot to restore and to decide what to keep and what to delete. We may enjoy a faster restore time, but there are risks that impact cost, efficiency, and operations in general. Also, snapshots are usually stored locally close to the storage system and therefore are not disaster-resistant.
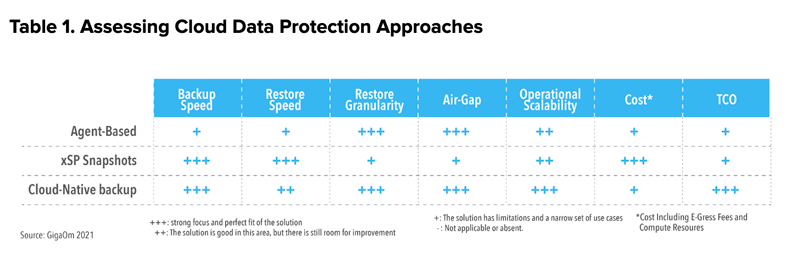
The third option: rely on a solution specifically designed for cloud operations. This approach usually provides the best of both worlds while minimizing cost and risk. The process is simple—the backup software takes a snapshot and then makes the necessary operations to index and store it efficiently in a different location. This enables the user to create consistent data protection policies and get full visibility on what is really protected and how. The user can also search backups to quickly find data to retrieve, and can also organize the schedule and even create the necessary air gap to protect applications against worst-case scenarios. Table 1 shows how these three options compare.
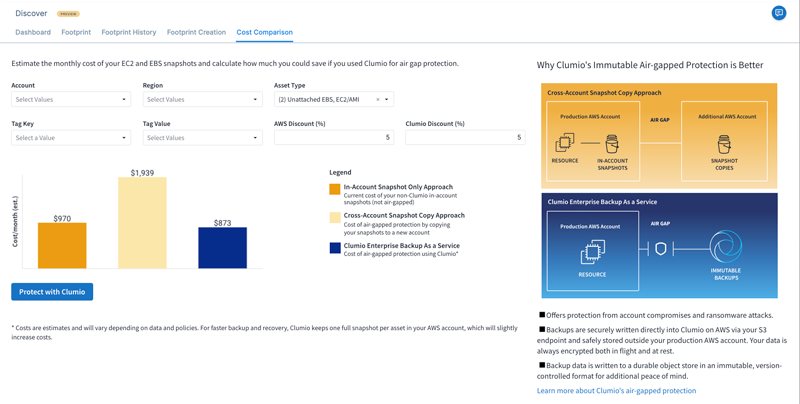
An example can be found in a recently launched product by Clumio: Discover. This product does more than just cloud-native backup. In fact, it combines the snapshot mechanism of AWS services with its own and integrates the two to give the user a seamless experience and the best overall TCO.
The solution is clever in that it provides the ability to manage AWS snapshots, independent of the backup solution used including AWS Backup, through the Clumio dashboard. This gives full visibility into protected compute and storage instances while adding the option to use Clumio advanced backup capabilities, via Clumio Protect, to enable indexing, search, file-level restores, and more. Clumio stores data in different locations, creating the necessary air gap to protect data in case of major system failures, disasters, or cyber-attacks. One of the features I loved the most in Clumio Discover is analytics, especially the cost control features that enable users to simulate combinations of native AWS snapshots policies combined with Clumio advanced backups over time.
Closing the Circle
Traditional data protection doesn’t work in the cloud. From the cloud provider’s point of view, snapshots are more than enough for operational continuity. If you want to protect your mission critical data and applications, you have to find a solution that is specifically designed to work efficiently in the cloud.
Efficiency in this case also means lower cost and operational scalability. In fact, traditional backup solutions are not designed to deal with the speed of change of the cloud, while snapshots alone are really time-consuming for system operators. The latter also creates cost issues related to snapshot orphans, retention management, replication, and recovery times for single files. These are all aspects of snapshot management that are often underestimated.
Keeping control of your data in the cloud is fundamental, but it is even more important to do it with the right tools that keep costs down while simplifying operations. In this scenario, products like Clumio Discover offer a compelling balance of usability, integration with the cloud platform, and cost control features that are at the base of a sustainable modern cloud strategy.