Commvault Unveils Clumio Backtrack - Near Instant Dataset Recovery in S3
Backups vs. Snapshots—they are not the same, you really need both




After 20 years of helping customers design well architected primary and secondary storage solutions, I’ve witnessed and participated in countless discussions around the value of backups vs. snapshots, though I’ll say that over time, the conversation seemed to evolve into settled law—Backups and Snapshots are complementary features but are fundamentally too different to compete for the same functionality inside of a data protection strategy. The lines, as they were drawn, followed this path of distinction:
Snapshots are a very effective mechanism that provides full point in time recovery of a host and is generally employed when the defined RPOs and RTOs are stricter than can be achieved by a full data recovery process from backup. Additionally, snapshots are effective with downstream refreshes of production systems into Dev/Test environments.
Backups, by comparison, are very effective mechanisms that provide:
-
More granular recovery options through the use of an index and catalog of all of the contents contained within the backup
-
Separation of data locality—essentially moving the data outside of the primary storage realm into a separate storage domain
-
Cost-effective long-term retention of recovery points
Meeting compliance goals and being audit ready with granular recovery
| The ability to look inside a backup by means of an Index and Catalog helps understand modification timestamps to individual files over a period of time. This is an incredibly important tool to have, as oftentimes the data that disappears is not the entire machine, but simply a file that was deleted and needs to be restored. File restores are important when it comes to proving compliance during an audit. Without an index and catalog, how does one provide proof of backup of any particular file? Would you now have to restore an entire instance and then search for the file or set of files? Audits typically ask for many different types of proof points across multiple different applications, etc. How would one solve that with snapshots? Typically, we see File Level Restores as over 50 percent of restore actions that occur within our Platform today. |
Without an index and catalog, how does one provide proof of backup of any particular file? |
Providing ransomware protection via separation of data locality
Ransomware attacks, which are one of the top security concerns for organizations today, not only look to compromise the primary data but they hunt for backup copies to compromise them too. This ensures that the primary data cannot be recovered from a valid backup copy. Therefore having air-gap backups which moves the backup data outside of the primary storage domain is a must to defend against such attacks. Snapshots do not provide this mechanism whereas a good backup solution does.
Taking the debate to the cloud
As I have shifted into a role at Clumio that is specifically focused on customers consuming public cloud, and more specifically, AWS, to my surprise, the conversation has been reignited, and the practice of using snapshots as a data protection mechanism has come back to life, or at least it appears to have. Initially, I thought it was due to the fact that cloud adoption was a bottom up approach, and the individual (ghost IT) teams became familiar with snapshots as it was offered ‘free’ in the platform. It seemed a simple enough strategy to be able to recall machines if they failed. The ghost IT idea was compelling, except now customers are migrating to cloud in a top down strategy, where there is more scrutiny and security becomes a forefront concern.
The more revealing truth as to why AWS snapshots are being used as “Backup” also has to do with the fact that customers believe that a better option doesn’t exist. Legacy backup vendors struggle to create a cost effective solution for the public cloud. The simple cost of running a backup software server/storage architecture stack in your VPC is a barrier to entry. As a result, these vendors’ unanimous response to solving the problem was to layer an orchestration tool on top of AWS snapshots. Essentially, they make it easier to manage snapshot instantiation and recovery but fail to provide the mechanisms discussed above needed to deliver a comprehensive backup solution.
Consequently, many customers we speak to today are still using AWS’s snapshot manager as their data protection strategy. Many openly acknowledge the lack of completeness with the strategy (and are relieved after they hear our story).
The challenges with snapshots in AWS
One of the distinct challenges that these customers describe is trying to understand which snapshot they need to restore from in order to deliver the correct data back to the end user. Again, this is due to the lack of any Index or Catalogue present around the snapshots. This may appear to be a trivial issue but the realities of restoring a file for an end user with no index or catalog is kind of like going on a treasure hunt and using a map made by your five year old who conveniently forgot to put any of the street names on the map and also forgot to put on any unique identifiers on the objects you were supposed to find in order to tell them apart from the other similar looking objects in the neighborhood. It’s easy to pick up a tree branch from under a tree, but how do you know if it’s the right branch, or even the right tree?
Analogies aside, let’s walk through the realities of this problem statement—you have a user request to restore a file, however, the user is not quite sure when the file disappeared. You are currently keeping 30 days of snapshots in your account. How would you approach solving the challenge of understanding which snapshot is the correct one to restore the file from?
Let’s begin to solve this problem using snapshots in AWS. The end user will be presented with a list of snapshots that describe the point in time when the snapshot was initiated, but that is all that they show. Since there is no index or catalogue to help me understand the contents of the files, I now need to start the process of manually searching for the file that was requested.
This process includes doing the following:
-
Identify the most recent snapshot
-
Create a volume from the snapshot
-
Find an available EC2 instance
-
Mount the newly created volume
-
Search for the file—if the file does not exist, start the clean-up process
-
Unmount the volume
-
Delete the newly created volume (important in your haste not to forget to do this)
-
Repeat the process above until you finally find the file
The challenge gets more complicated if the file in question has multiple versions. Now one needs to understand when these changes occurred. Again, no index or catalog to highlight this.
| When I performed the test in earnest, and I was in a rhythm, it took me approximately 35 minutes to find the file I was looking for. I ended up running the above process 8 times to find the file. If the file was further down the stack, it easily could have taken me an hour or more of my work day to find that file. Not really how I envisioned spending my day, and certainly not something my boss would want me to be doing either. In large scale environments, it is easy to imagine file restore requests occurring multiple times in any given day or week. Imagine this same problem statement at scale! |
With Clumio, I was able to accomplish the same action in 35 seconds. |
With Clumio, I was able to accomplish the same action in 35 seconds, delivering the requested file quickly and reliably back to the end user. That is the advantage of having the right tool for the right job.
So why should someone implement both a snapshot and a backup strategy?
Snapshots provide:
-
Fast instance recovery from accidental full instance deletion
-
Point In Time copies of databases to restore production environments as well as to refresh lower environments
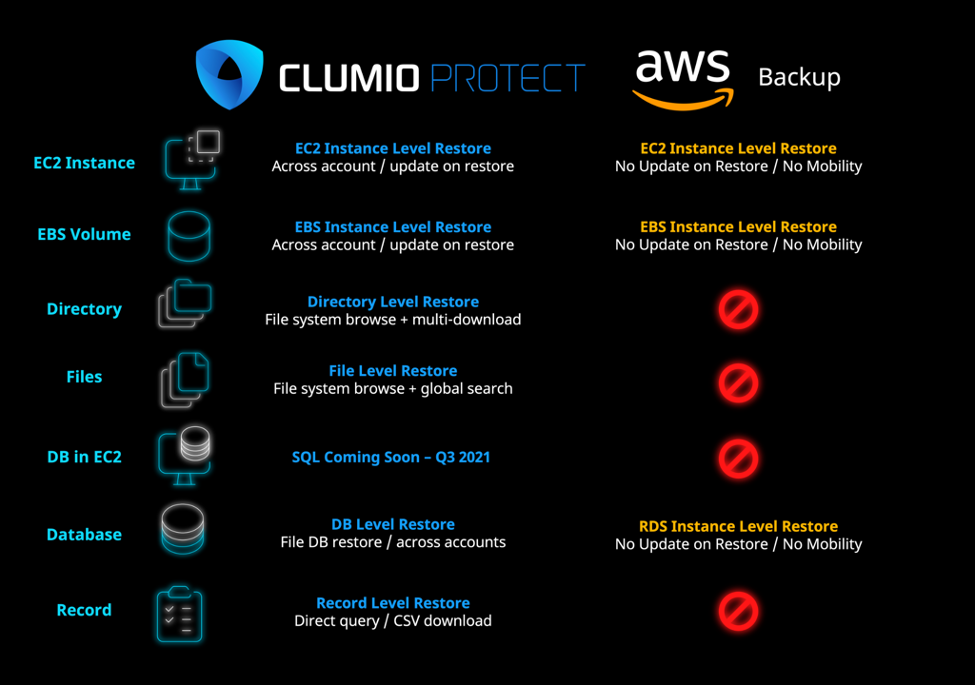
Backups with Clumio provide the below benefits:
-
In addition to Point In Time copies and restores of databases, get rapid granular restores with searchable access to files and folders
-
Simplicity of managing data protection and data compliance at scale (Index and Catalog)
-
Increased data security through our inherent air-gap protection
-
Cost efficient retention of data for long term
The great thing about Clumio is that while it only took me 35 seconds to restore the file, it also only took me 15 minutes to set up from scratch and start protecting my data from ransomware attacks. I can also now manage my backups and snapshots from the same interface—a perfect combination of the dual approach strategy.
OK, fine—Clumio can solve that problem 10x faster. We didn’t budget anything for additional cost to our data protection strategy. THAT’s OK. Clumio actually costs less than what you are paying on snapshots today (this is already a sunk cost for you, Mr. Customer), while providing all the benefits of true backup and recovery—Security, Performance, Granularity, Data Mobility and last but not least—SIMPLICITY.
Why not check it out? Secure, Simple, Fast, SAASy.
