Commvault Unveils Clumio Backtrack - Near Instant Dataset Recovery in S3
Retain & Retrieve: Clumio’s Deep Dive into Amazon RDS Backup





Most organizations need to retain data for long periods for regulatory requirement audits, company policies, and compliance. These organizations are required to spend large amounts of money and effort to retain backup data for the long durations to ensure they can retrieve the data when needed. To help organizations with their long-term retention requirements, Clumio developed Extended Retention and Granular Record Retrieval for Amazon Relational Database Service (RDS) (Backup for Amazon RDS ). This feature will ease an otherwise excruciating process for the organizations.
This blog post is the second part of the three-part deep-dive series. In part 1, I went through an Amazon RDS Operational Recovery Deep Dive with Clumio. Of all the features available for Clumio, to me granular record retrieval is the most exciting one. I’ll share the highlights in this blog and we will dive deep into this feature through a thought-provoking functional demo. It is a must-have capability for the organizations that need to store and retrieve data over a long period.
If you run RDS today, here are the top 5 reasons why you need to check out Clumio’s backup as a service for extended retention and granular record retrieval
1. Fast and Efficient over Traditional Methods
Imagine getting a record request for historical data several years from now to satisfy audit requirements for your on-premises database, or IaaS-based databases. The process is painful, requiring pulling data from Iron Mountain or a cold storage in the cloud which could take weeks. Now that you have moved to the cloud using RDS, life is much easier for operational recovery needs. But if you use snapshots, retrieval of long-term retained data could make it painful again. Clumio backup as a service gives you an enormous advantage over traditional backups and classic snapshot managers when it comes to retrieving historical records. Amazon RDS, a DBaaS, makes database administration extremely easy but, unfortunately, Amazon RDS has a big gap when it comes to data protection. This is where Clumio’s backup as a service comes in and complements RDS by filling those data protection gaps which will catapult Amazon RDS to the enterprise level.
For more context, read Removing Data Protection Roadblocks for Amazon RDS by Abdul Rasheed (Sr. Director of Product Management at Clumio) and his spectacular vision to take Amazon RDS mainstream.
Now, let us compare traditional retrieval methodologies versus the Clumio data retrieval process. The retrieval time differences between Clumio and others are huge, as seen in Figure A:
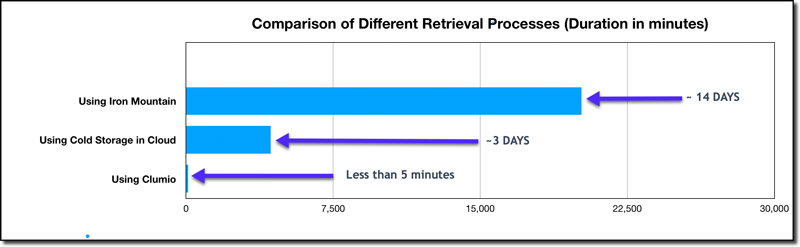
- Using Iron Mountain: The retrieval process begins by recalling the tapes from Iron Mountain. After that, the entire database needs to be restored onto a sandbox environment which is a very time-consuming process as IT administrators need to provision the underlying infrastructure for the database. This painful process needs to be repeated even if the data is to be retrieved from just a couple of tables. It takes considerable time and effort. The complete process would take at least 2 weeks.
- Using cold storage in the cloud: Some organizations have started storing data in the cloud. For them, the retrieval begins by downloading the database backup data to their data center or cloud account. Depending on the size of the database and network, this will take considerable time. They need to build or provision the infrastructure for the database and install the database engine that they were using several years ago. Then they need to recover the entire database even if they need to retrieve just a couple of tables. This process would take 3-5 days depending on the size of the database.
- Using Clumio Backup as a Service: Now, the retrieval process with Clumio would take a few minutes – literally. The tables or records which need to be retrieved can be directly queried. That is it!
2. Disaggregating the Data from the Database Engine
Keeping data for long-term retention with PaaS services opens up another challenge: getting access to the data on a supported RDS database engine. A customer recently mentioned this challenge when trying to restore a 1 year old snapshot and having the restoration process fail due to AWS’s lack of support for the database engine. The good news is that Clumio backup as a service for RDS creates logical backups in a time-series data lake for retrieval. It is stored in the parquet format for future consumption and makes the data independent of the database engine. We can directly query this data down the line without the need to worry about finding an old database engine that may or may not be supported anymore. This is the most unique and powerful aspect as it liberates data from the database engine. Since the data is logical and decoupled from the database engine, we can retrieve it and restore it to a different database engine.
3. Simple and Easy to Use
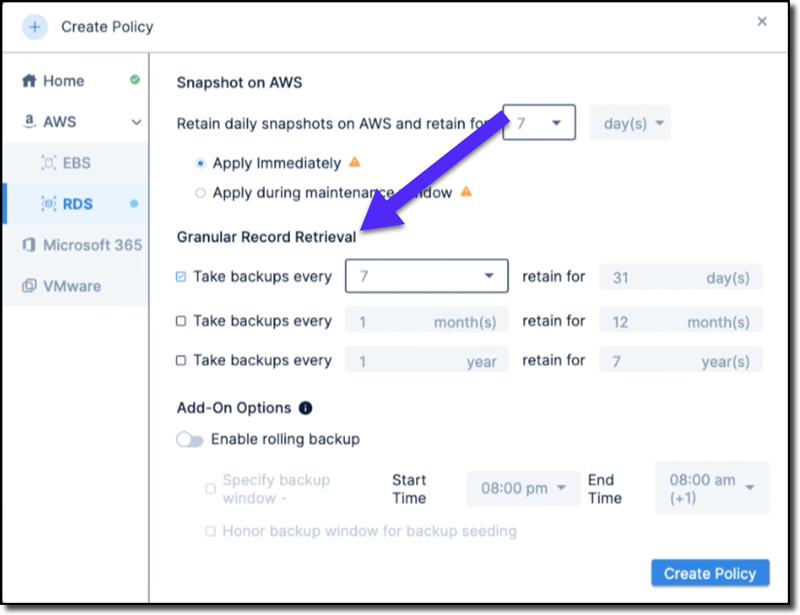
The entire granular record retrieval process is straightforward and easy to use. The process begins with the creation of unified policies (shown in Figure B) for setting up extended retention for RDS databases to the retrieval of data is easy. The granular backups can be taken weekly, monthly, and yearly and can be retained for seven years.
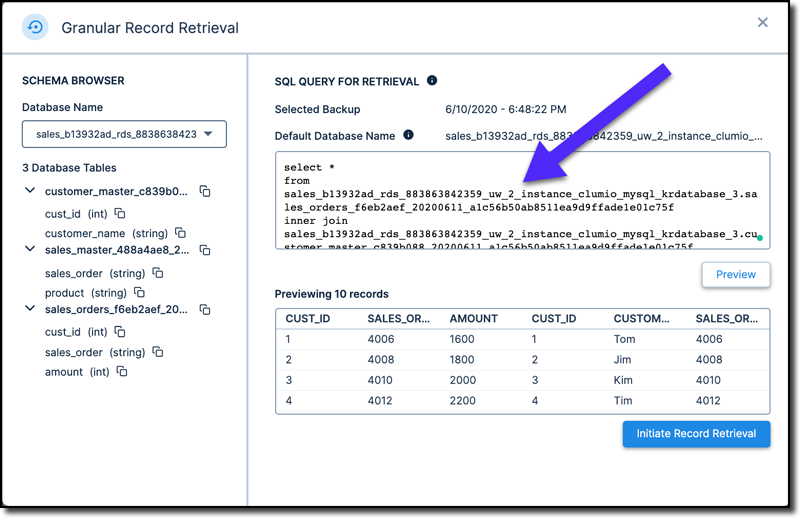
4. Running Advanced SQL Queries to Retrieve Data in Minutes
In most of the transactional databases, tables are normalized. That means there is no single table that stores all the data; we need to query multiple tables to get all of the data. With Clumio, we can execute complex SQL queries directly as if we are running it on a database directly, like complex SQL queries with JOINS and UNIONS. Figure C shows granular record retrieval advanced SQL editor to execute queries.
5. Absolutely No Risks
With Clumio Backup as a Service, there are no challenges of building the infrastructure for the entire database and finding the binaries of old database engines. It is a considerable challenge to find such old database binaries, which is the case with using Iron Mountain and cold storage in the cloud. There is no need for a recovery of the complete database. Hence it makes it altogether a risk-free data retrieval process.
About the Demo:
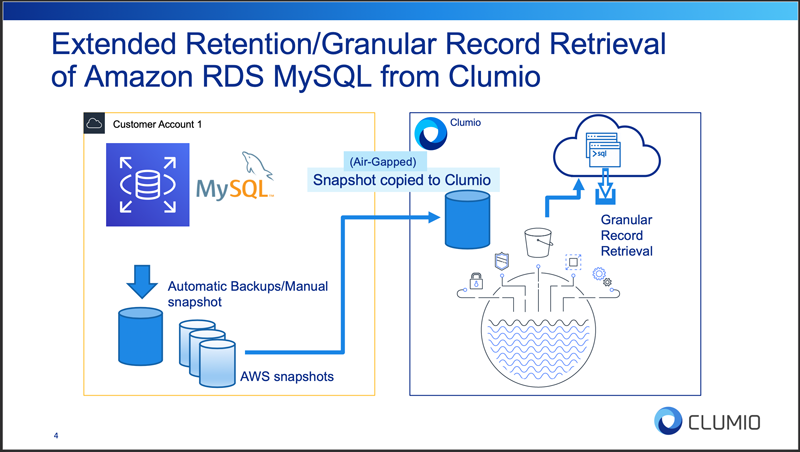
MySQL RDS database version 5.6 is used for the demo. It is populated with 500 GB of data using load generator sysbench. Once granular record retrieval is enabled, Clumio uses the AWS snapshots. AWS snapshots are encrypted and sent to the Clumio service. We process the AWS snapshots to create a logical backup of the database. This logical backup is stored in S3, and it can be queried directly. Figure D shows the complete data flow of the granular record retrieval process.
Check out the complete demo:

Summary
Clumio Backup as a Service is an unbelievably fast and straightforward way to retrieve granular data even after several years without installing the entire database. While contemporary methods that use Iron Mountain and cold storage in the cloud present significant risks that are introduced through using snapshots of old database engines that may no longer be supported or through time consuming methods that are inherent in legacy platforms. Clumio has solved for these challenges by separating the data from the underlying infrastructure elements and introduced a direct query methodology built around our catalog and index technologies that allows you to quickly find exactly what you are looking for without having to wait for lengthy retrievals from Glacier or other archive storage tiers. Clumio has absolutely no risks concerning database installation or in the recovery process. In fact, the most significant benefit of Clumio in this case is that the data gets disaggregated from the database engine, so there will be no database engine support issues. Overall, using Clumio Backup as a Service is a must-have where there is a need to store the data for long periods.