Commvault Unveils Clumio Backtrack - Near Instant Dataset Recovery in S3
Why Clumio Beats Cohesity





We’re in the midst of a colossal change for enterprise IT. With data lakes, cloud-native apps, AI and ML, the world has moved on very quickly from the traditional hardware + VMs oriented approach to IT. At Clumio, we’re riding this wave, having created the industry’s first backup and recovery solution for cloud-first applications, data lakes, and big data workloads. Of course, you don’t have to take our word for it. Jim Boyer, CIO, Rush Memorial stated “Clumio has been a disruptor that’s taken us to a different level. It would be great if every vendor worked like this.” The result for Rush Memorial was a massive reduction in complexity needed to manage their data. Now they can focus even more on their mission of leading the way in healthcare by offering their community the most advanced medical experience.
While our competitors have been making noise, we have been building. From the industry’s first integrated, cloud-native data protection solution for AWS EC2, EBS, and RDS that took the industry well beyond snapshots, we also delivered the first RDS solution that decouples the data from the infrastructure, and built a time-series data lake with record and row-level retrieval via direct SQL query. And this is only the beginning for Clumio.
While legacy vendors have been busy trying to pivot themselves away from backups to “data management” and data security”, throwing all sorts of buzzwords like “cyber resilient”, we are busy reinventing backups for the cloud. Let’s dig deeper into three aspects:
Clumio Data Management SaaS Delivers the Ultimate Simplicity
The best solutions provide a seamless user experience across all aspects of the service. In the cloud today, data is scattered across many cloud services, which increases the potential for complexity. At Clumio, we made the decision, based on customer feedback, that our service should be effortless to manage and consume across a wide range of data sources. We decoupled data from the infrastructure and built a time-series data lake, so customers could get to their data faster without incurring the high costs of restoring to a new instance.
The likes of Cohesity and Rubrik, on the other hand, have clusters on-premises in hardware, S3 offload to the cloud to make hardware cheaper, cloud clusters that can run in the cloud for a lift and shift option, snapshot manager for AWS backups, and myriad other disparate tools that are still VM-centric and offer limited workload coverage.
Today, Clumio’s backup as a service cloud platform protects AWS native services, VMware, and Microsoft 365 all in one platform, with many more data sources, clouds, and data management solutions to come. But what is the user experience like?
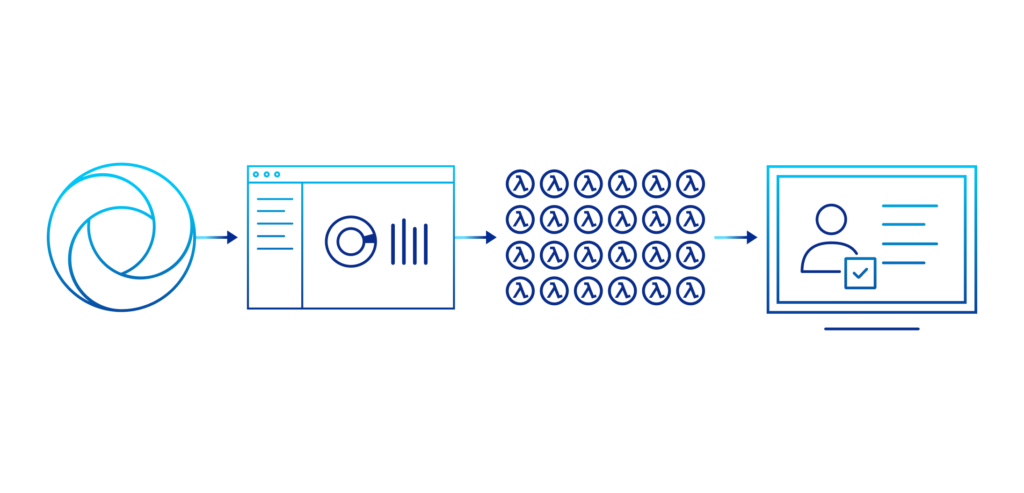
Architecture Matters - Cloud Native vs “Refactoring”
Building a platform in the cloud is not a trivial task. Decisions made at the onset have substantial impact on the benefits and experience customers have with the solution long-term. One thing is for sure; the more you natively integrate with cloud native APIs and resources, the better the results in performance, scale, economics, and the ability to use new services the cloud provides directly. While this might sound rudimentary, the impact will be felt in all services, especially beyond data protection into “Data Management.”
With Cohesity positioning themselves in Data Management as a Service, we would have expected them to start fresh with a cloud native platform, but we were let down when their VP of Product announced “and we have taken the platform and **refactored** it into a series of cloud-native services.”
Translated a different way, it appears that they took what they built on their hardware appliances, and ported it to the cloud. This trade off of refactoring or porting, has two significant downsides:

- Architectural inefficiencies: Our guess is Cohesity used the same Cloud Edition released a while back marketed for test/dev and DR. Production use cases were not recommended, due to high levels of inefficiency, costs, and limited scale. Their Cloud Cluster is the ultimate “lift and shift” with a bunch of EC2 and EBS volumes emulating their hardware nodes in the cloud. Cloud Edition never took off as costs were much higher than on-premises with near zero benefits of cloud agility. Their recent offering has been refactored, which we understand to mean it’s using S3 instead of all EBS. Cohesity will either take the inefficiency off their margin or pass it on to the customer. I think we can all agree that if you were building a new cloud platform, this would not be the best route; but for Cohesity, it probably was the easiest to get to market.
- Compute Scale: Software development in a finite computing model (running on nodes of hardware) is very different from software development in an infinite compute model of public cloud. In the data center, compute is running all the time and is a fixed sunk cost, but the cloud is really different where you pay for every compute cycle. When building a platform in the cloud, functional computing drives benefits of efficiency along with parallelism. This results in lower costs, faster backups and restores, and extension into use cases beyond backup.
Clumio, on the other hand, has absolutely no dependencies on legacy backup constructs. Clumio’s data path is built on Lambda functions—decoupled, stateless cloud resources that scale dynamically with demand. In addition to protecting the broadest range of AWS data services, Clumio also has the highest scale for any backup technology today.
Clumio is architected as a high performance data pipeline, transferring even streams to a secure, immutable data lake that scales infinitely, and delivers industry-leading RPO / RTO performance.
Unlike legacy vendors that have all sorts of licensing fine print, minimum cluster sizes / commits, and potentially even hardware, with Clumio, you simply login, connect your AWS data sources, and you’re up and running. All our pricing is publicly available at clumio.com/pricing, and customers pay us for only what they choose to protect, down to the byte.
Clumio doesn’t pretend to be a “single pane of glass”, nor do we want to
There are a dozen different backup vendors aspiring to be your single pane of glass for data management, so it’s safe to say that none of them will be. Our approach is radically different. We like to meet customers where they are. If they’re a platform services engineer, they can invoke Clumio through Terraform. A cloud operator can use Clumio through the UI. A devops engineer building resilience into their data stack can use Clumio’s API. A site reliability engineer could create new AWS accounts for developers with Clumio baked in with CloudFormation, so that any new app they write is protected.
Closing Thoughts
As goes primary, so goes backup. If you moved to the cloud to take advantage of cloud-native technologies, your backups should leverage that too. Unlike the likes of Cohesity, Clumio is built on the most advanced computing and data architectures, is super simple and transparent to use, and delivers incredible performance at scale. If you’ve ever used platforms such as Snowflake and Datadog, you can expect a similar level of user experience, performance, and support from Clumio.
