Commvault Unveils Clumio Backtrack - Near Instant Dataset Recovery in S3
3 steps to a strong data retention policy





I often have customers ask for recommendations on data retention, mostly in reference to creating their backup policies. At times, I advise on data retention strategies across enterprise functions.
I thought it would be beneficial to share our baseline on data retention recommendations, for backup purposes and in general.
But, before I get to the “answers” let’s talk about the why behind data retention.
Data is retained for three reasons:
- The data provides enterprise value;
- To reduce technology and information risk;
- To meet legal requirements.
Information for enterprise value
Information has become like any other commodity; knowledge, data, or information can be exchanged for other things of value. A simple example is trade secrets or information used in the production of highly specialized or unique goods that are then themselves valuable. Much of the value of the goods comes from the unique ability to produce them. Loss of that information can create economic setbacks for an organization or individual.
More recently, data is being looked at in a new way. Information that was easily overlooked previously is being re-evaluated to determine its strategic and operational importance. Additionally, innovations in machine learning (ML) that led to ChatGPT and other large language model tools have presented a new way to understand our data. The catch is, to make large language models meaningful you need good data and lots of it. Everything from user chats to customer powerpoints hold examples of how we use and structure language to communicate about a business. This information can be used to start developing models that either make jobs easier and faster, or provide new ways to interact with the information. Organizations are now looking at retaining data that was previously thought of as “too expensive” to retain, because the new value makes it worthwhile.
Retention of this information is therefore critical. Data loss has an extreme impact on organizational value or competitive strategy.
Reducing risk
Secondarily, businesses must manage the risk associated with indirect financial losses stemming from data loss as a result of failure in technology, human errors, or offensive attacks (cyber attacks).
All three of these – technology failure, human error, and offensive attacks – can result in material impact to data availability. Or simply put, data that can not be accessed causes downtime and therefore financial losses.
We need to weigh these factors when determining what data we retain and how we retain it.
The classic example that has become the standard “why” we retain data is ransomware. It’s easy to point to others and say “Look what happened to them” as it’s almost always a dramatic news story when ransomware attacks cause impact.
The reality is, we should take a more data-driven approach to risk reduction. Human errors cause more damage everyday than ransomware attacks. Security Week’s recap of the 2023 Verizon data breach reports highlights this with a simple statistic. Roughly 25% of attacks were ransomware while 75% had a human error (typically from social engineering or other ) related to the attack.
The variety of risk scenarios we need to account for is massive. I can’t summarize risk quantification in a simple way, but it should be a large factor in how we determine what data needs to be retained and for how long.
Meet legal requirements
And, last but not least – there are legal requirements around retaining business records and data. This varies by jurisdiction and industry vertical greatly. If you’re in certain healthcare services markets, it could be up to the lifetime of an individual or more.
Finance records related to transactions, communications, financial books and more need to be retained for 7 years.
This often is the “hard line” for data retention. The soft cost of risk-reduction can be a hard sell. Same for the value of data for ML and big-data processing. We don’t know the upside for many of those types of projects going into them.
But, obligatory legal retention is very clear. You can point to the text and case law in which fines are established.
If you had to use only one factor in determining retention lengths, this would be it.
We’ve highlighted a few key data retention requirements for your reference:
Determining how long to keep data
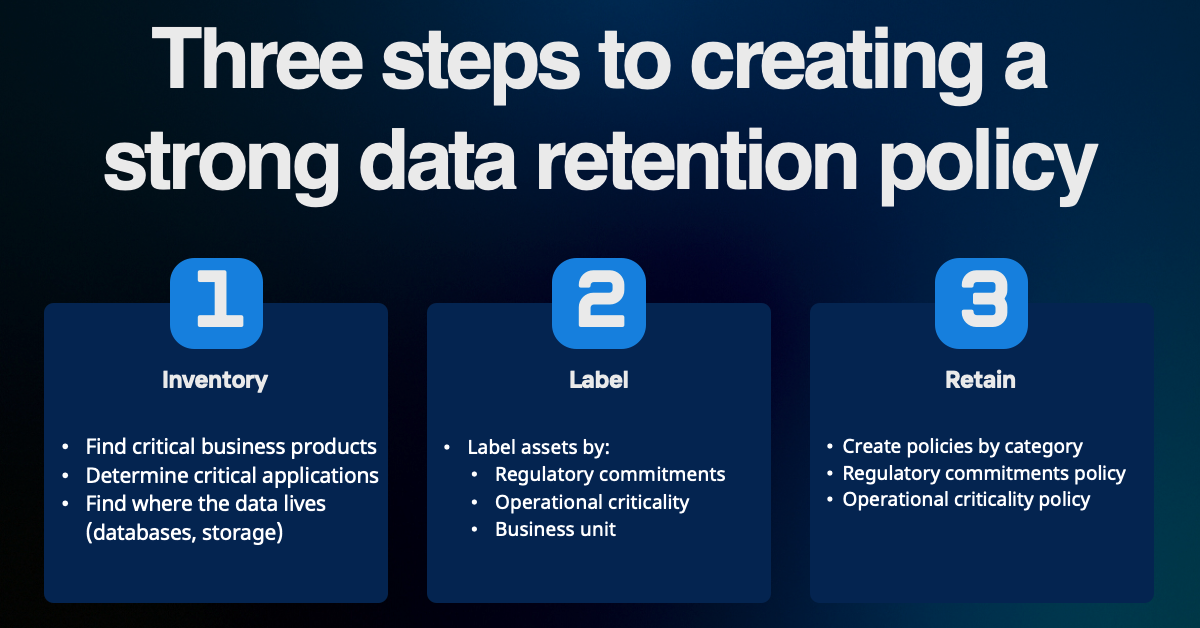
Clearly data needs to be retained for many reasons. But how should you develop a strategy? Let’s use a three step process.
Step 1: Inventory
If you do not have an inventory of critical data, start by looking at what products or services generate the most revenue in the business as well as areas of the business that hold regulated data. This should be cross-functional. Finance, product, and legal teams can all help point you in the right direction.
Once you know what the most critical and regulated parts of the business are, you can ask the supporting teams which infrastructure components host the data. It might take a little digging to get to the right DBA or cloud engineer if this is a net new activity for the business, but a little diligence will get you the results needed.
Step 2: Label
Once you create an inventory of business applications and technologies that are critical you can assign labels to the assets. Lets use a tactical example for a simple idea of a healthcare system running in AWS.
Web front end: EC2
Backend: Patient files (generated PDF and images) S3
Core records: RDS
The labels might be:
EC2/EBS: Data-Retention: Bus Critical
S3: Data-Retention: Bus Critical+Regulatory
RDS: Data-Retention: Bus Critical+Regulatory
Step 3: Retain
For each of these you can map the retention period to the tags.
Bus-Critical from our example may get an hourly Recovery Point Objective (RPO) with 14 or 30 day retention periods.
Bus-Critical+Regulatory may get an additional policy of monthly RPO with 30 year retention (in healthcare, data retention is based on the services provided).
Great… but give me an easy answer!
For cloud data
Let’s start with an easy category that we at Clumio are asked for all the time: cloud infrastructure. For critical production cloud infrastructure data (EC2, Databases, S3) our baseline recommendation is the following:
- 14 day retention of a daily backup
- A weekly backup kept for 4 weeks
- A monthly backup kept for 12 months
- And then 1 yearly backup kept for X years where X is your legal retention requirements
You can adjust this based on the role and criticality of an asset.
We also recommend using point-in-time recovery, especially for databases and S3. Any data source that is highly transactional benefits from being able to restore to a specific time with specific records, tables, objects or files. This reduces your RPO drastically and limits the RPO impact to specific data, or is able to create a “zero RPO” capability.
For your enterprise data outside the cloud here are my guidelines:
- Infrastructure (servers etc) – 14 day retention of daily backups
- User devices – Provide cloud (M365 Drive, Google Drive) storage and determine backup needs based on business model. (There is no easy button for end-users, it’s too variable in both cost and criticality.)
- Security events – 5 years, or based on legal team guidance for your operation regions
- Security telemetry – Should be based on volume of data vs. usefulness. Identity-based logs and endpoint 5 years, all others 2 years or if cost is significant, less.
- Audit logs for SOX compliance – 7 years
- Operational technology and infrastructure data (configurations, network configs, designs, templates, IAC, etc.) – Use revisioning system like GIT or similar to maintain data for life of system + 2 years
- System documentation – Life of systems + 2 years
- IP – Lifetime of the company + have an archive strategy
- Customer product data – Based on customer expectation and product. Easy answer – lifetime of the customer + reasonable off-boarding time based on service offered.
- Customer, sales, marketing data – Based on legal guidance to meet privacy requirements; roughly, the required time for usefulness for a purpose, then deleted
- Finance data – Depending on industry, and structure including public/privately held. SEC / SOX and other regulations require 7+ years of data retention
The reality is, the retention of data should be a legal, technology, and risk decision and include stakeholders from the teams that own those pillars in the business.
Here is a rough reference table for legal requirements (this is not legal advice, think of it as loose guidance). You can use this as a starting point for your research or questions to ask your legal counsel.
| Framework/Regulation | Retention |
| NIST (Elected framework) | 3 years |
| ISO (Elected standard) | 3 years |
| PCI (Obligatory contractual) | 1 year |
| HIPAA (Obligatory US Law) | 6 years |
| SOX (Obligatory US Law) | 7 years |
| GLBA (Obligatory US Law | 6 years |
| FINRA (Obligatory US Law) | 7 years |
| SEC (Obligatory US regulation) | 7 years |
| FDA Pharma (Obligatory US regulation) | 7 years |
| FDA Food (Obligatory US regulation) | 2 years |
| NYS DFS 23 (Obligatory NYS Law) | Business case dependent |
| Healthcare data (Obligatory US regulation) | Months to lifetime, but not forever |
| EU: CyberSecurity ACT, Cyber Resilience ACT, DORA | EU: CyberSecurity ACT, Cyber Resilience ACT, DORA |
The easiest answer of all: De-risk and simplify data retention with Clumio
Now that you have a data retention plan, you need to enact it. The easiest way to do so is by automating air-gapped backups with Clumio. It’s simple:
- Connect your AWS account to Clumio
- Set backup policies with Recovery Time Objective (RTO) and retention according to your retention requirements
- Apply the policies to data with Protection Groups and Rules
- That’s it. Your data will automatically be backed up, and you can view reports whenever you need them.
See for yourself with a personalized demo.